 IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
并发编程之Redis(二):Redis数据持久化及故障恢复方案

为什么要做持久化?
- 原因
用过Redis的应该都知道,其数据都是保存在内存中,这也是它性能这么好的主要原因;但是这样就会带来一个问题,就是当Redis进程挂了或者机器挂了之后,内存中的数据就没了。那为了保证数据不丢失或者尽量少了丢失,我们希望数据能够落地到磁盘中,来降低故障发生之后数据丢失的可能性;当再起启动服务的时候,通过持久化的磁盘数据,快速恢复到内存中; - 持久化的作用
- 核心作用:
故障恢复,如果一切都按我们想象的去发展,就可以不存在什么持久化;往往事与愿违,你越不想发生的事情偏偏他就发生了。 - 数据回滚
为什么要说数据回滚?既然是人写的代码,不可避免的就可能有Bug,如果上线的一个功能,因为Bug的原因,导致当前redis中缓存的数据错乱或者更加严重的事故;那么我们上线的服务可能会紧急回滚;同时可以借助之前的持久化文件,将Redis中的数据同样也回滚到发布之前的状态;
- 核心作用:
- 如何做好一个企业级的持久化?
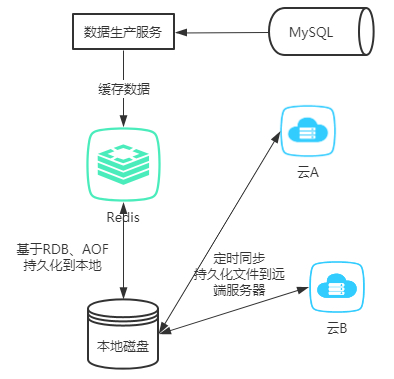
上面有说到,持久化的核心作用是为了故障恢复,既然redis可能故障,机器同样也会故障;就算是数据落到磁盘了,同样也可能因为磁盘故障,导致数据丢失;如上图!为了做好一个企业级的持久化方案,我们需要将持久化文件定期同步到云端或者远端的服务器,做好分布式存储,来防止因为机器故障带来的灾难性数据丢失。
Redis提供的持久化方案
Redis官方提供了两种持久化方式,快照(RDB)和 AOF日志,默认情况下,Redis是开启的RDB,关闭了AOF。
快照(RDB)
-
什么是快照?
快照其实就是一次全量备份,其数据是以二进制二进制序列化的形式存储; -
快照持久化可能产生的问题?
Redis是一个单线程程序,此线程需要处理客户端的读写请求,同时还得处理程序内部的逻辑读写;当Redis需要进行持久化的时候,必定就会产生IO操作,IO是比较耗时、耗性能且IO操作又不能使用多路复用;还有个更严重的问题就是,Redis在持久化的时候,数据可能还在发生变化,比如,一个大key,持久化了一半,结果客户端把他给改了,那这会儿该怎么办?是同步,还是不同步? -
Redis如何解决快照问题?
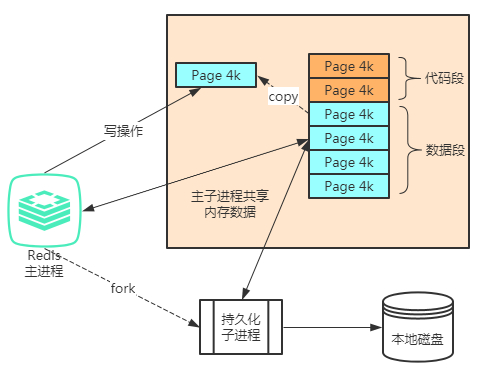
Redis使用操作系统的**COW**(Copy on Write)机制来实现快照持久化,持久化触发会调用glibc的函数fork一个子进程,然后持久化的操作全部交由子进程去完成,父进程继续执行来自客户端的请求;如上图,子进程产生的时候,和父进程共享内存中的代码段和数据段;linux的机制为了节约内存资源,尽可能的将他们共享,因此,子进程产生的时候,几乎不会带来内存增长;当主进程发生写数据的时候,其实也就是对某一页的数据进行修改,因此会Copy出一份相同的数据,然后对复制出来的那一页进行修改,子进程看到的数据依然还是原来的那份;这样主进程的操作不会受到影响,子教程同样也不用担心数据会发生变化了,当他产生的那一瞬间,数据相当于凝固了,这样他就可以安安心心的进行序列化并持久了。数据持久化的操作很快,就算是这个期间来了大量的写操作,也最多只会增加原来2倍(所有页都被copy了一份)的空间 -
Redis快照持久化的规则(默认开启)
// save <seconds> <changes> // 检查规则为 时间范围生成的数据变化次数 // 默认redis为以下的检查点;每一分钟有10000个key发生变化,就持久化一次,其他同理 save 900 1 save 300 10 save 60 10000 -
快照文件保存的位置
// 可以通过conf的dir参数进行配置路径 dir /var/redis/6379/data/ (根据自己情况选择合适的路径)
-
手动RDB同步的指令
// 同步持久化 save // 异步持久化 bgsave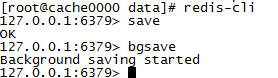
-
RDB的优点
- Redis会定期生成持久化文件,因此非常适合做上面说道的企业级
冷备方案;定期将这个文件复制备份到其他服务器,防止数据丢失 - RDB的性能要比AOF的高,因为他对Redis的写操作几乎没有什么影响
- RDB文件在数据恢复的时候,相比与AOF要快;因为起存储的是二进制序列化数据,直接加载进来即可
- Redis会定期生成持久化文件,因此非常适合做上面说道的企业级
-
RDB的缺点
- 相比与AOF,数据丢失的可能性更大,丢失的数据可能更多;因为如果出现故障,从上一次持久化到当前这个时间段的所有数据可能都丢了
- fork子进程的时候,如果数据量大的时候,可能会导致客户端毫秒级或者秒级别的服务暂停
AOF
-
什么是AOF
通俗一点说,其实就是所有写操作的一份日志记录文件;当需要对数据进行恢复的时候,就把整份日志进行回放,即可完成整个的数据恢复;当Redis收到客户端的写操作之后,经过参数校验,逻辑处理,没有问题之后会将指令写到AOF日志;也就是说,整个过程是先执行指令,再写日志; -
AOF重写(rewrite)
AOF是将所有的写操作记录日志,那么随着时间的推移,这个日志文件会变得越来越大,同时也会很臃肿;因为里面可能记录了大量不起作用的日志,比如,一个key a,执行了一下三次操作,set a 1,set a 2,del a,那么在AOF中,其实保存了3条日志,当要做数据回放的时候,这三个动作都得做一遍,但是三个操作其实是没有任何意义的操作,因为第三步已经将其删掉了;因此Redis会定期对AOF日志进行瘦身;原理就是开启了一个子线程,将Redis中的数据转换为操作指令,在序列化成AOF文件,序列化完毕之后,会将操作期间产生的写操作追加到新的AOF中去。// 手动rewrite的指令 bgrewriteaof- rewrite策略参数
// 可以在redis.conf文件中通过以下参数配置rewrite策略 // 表示当前的AOF文件相比与上次rewrite之后的大小增加了百分之多少,默认是100% // 如上一次rewrite后是100M,当大小超过200M之后就会触发rewrite auto-aof-rewrite-percentage 100 // 上面的参数触发之后,还需要和这个参数进行比较 // 比如上一次rewrite之后AOF文件之后10M,当达到20M后上面条件会触发 // 但是他总的大小依然小于最小值64M 所以不会触发rewrite auto-aof-rewrite-min-size 64mb
- rewrite策略参数
-
fsync
既然是每一次操作都将数据刷到日志文件,那么是不是就意味着数据不会丢失呢?不然!同样也可能会丢失1s的数据,当进行日志写操作的时候,其实是写到了OS Cache中,然后由操作系统定期将Cache中的数据持久化的磁盘;Linux的glibc提供了fsync(int fd)函数来强制将指定文件刷到磁盘,Redis默认是采用的1秒刷一次的策略,因此,就可能造成1s数据丢失的情况; -
能够保证数据不丢失
既然是1s刷新一次,能否每次都刷?是可以的,但是我们使用Redis的目的就是为了提高性能,实现高并发,如果采用了每次都刷盘的方式,将大大降低Redis的性能,可能得不偿失。具体的刷新策略可以通过appendfsync方式设置appendfsync everysec // 该参数有三个值 // 1. always 就是上面所说的,每次写操作刷一次磁盘,他可能保证数据不丢失,但是性能很差 // 2. everysec(默认) Redis每一秒刷一次磁盘 // 3. no 标识Redis不执行刷磁盘的操作,只是将数据写到OS Cache中,具体什么时候刷磁盘由操作系统决定 -
AOF的优点
- 可以保证数据更少丢失或者不丢失的风险
- AOF以append only的模式进行写入,所以不存在寻址,性能很高;以追加的形式,文件不会破损,就算出现破损,也只是出现在文件尾部
- AOF rewrite对客户端的操作影响更小
- AOF以可读性很高的方式进行存储,因此可以用来做误操作的数据恢复;比如说因为误操作执行了flushdb或者flushall将数据删除了,那么在下一次rewrite之前,我们可以采用停止redis服务,将AOF中flush的执行删除,再回放的方式将数据恢复
-
AOF的缺点
- 因为写操作多一次文件操作,因此开启了AOF的QPS相比于要低于RDB的方式
- 相同数据,AOF的持久化文件要比RDB的大
- 数据恢复的方式相比与RDB来说脆弱一些,容易出些Bug,导致恢复出来的数据和之前的数据不一致
- 不适合做数据冷备
企业级的持久化如何选择?
基于RDB和AOF各自优缺点,企业级的持久化策略不能仅仅使用RDB,也不能单纯使用AOF;因为RDB可能造成更多的数据丢失,AOF不太适合做冷备、数据恢复较慢、容易出Bug,因此,常用的策略就是两种方案共同使用;既能保证数据尽可能少的丢失,同样又有一个非常好的冷备方案;在特定业务场景或者特定业务,可以考虑只选用其中的一种,这个就属于特例了。
-
新安装的Redis开启AOF(只针对新装)
// redis.conf(/etc/redis/6379.conf)中的appendonly参数设置为yes // 注意,这里只是针对新安装 appendonly yes -
已经存在数据的Redis开启AOF
(特别提醒!特别提醒!特别提醒!不要和新装一样直接修改配置文件开启,数据会丢的!数据会丢的!数据会丢的!)-
直接修改数据丢失的问题分析
当Redis通过RDB保存数据之后,数据会持久化到dump.rdb文件中;当我们通过配置文件(6379.conf)直接开启AOF,Redis在启动的时候,会自动创建一个为空的appendonly.aof,当加载持久化数据到内存的时候,如果持久化采用的RDB+AOF的当时,那么就默认使用AOF进行数据恢复,但是当前appendonly.aof文件是新创建的,因此加载大内存的数据就是一个空库了。知道问题之后,就可以通过一下步骤去开启; -
第一步,appendonly no的情况下启动redis,保证数据能通过dump.rdb文件载入内存
-
第二步,通过redis-cli 连接redis服务
-
第三步,通过设置临时参数(重启会失效)开启AOF,此时,Redis会基于最新的内存数据生成aof文件
config set appendonly yes -
第四步,确认基于最新的Redis数据,生成了appendonly.aof文件
-
第五步,redis config配置文件中开启appendonly
appendonly yes -
第六步,优雅关闭,重启redis
redis-cli shutdown cd /etc/init.d ./redis_6379 start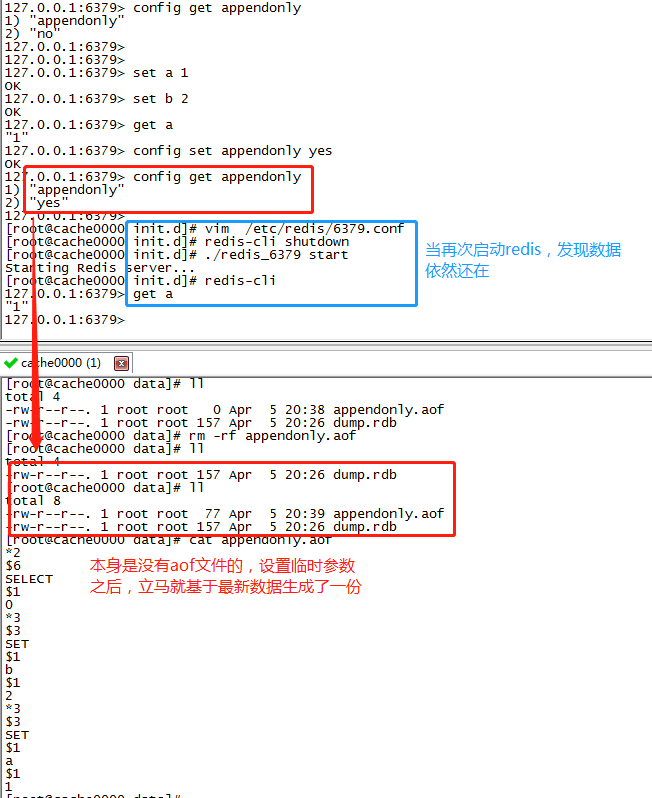
-
Redis冷备
这里的冷备是基于RDB的dump.rdb文件进行,通过脚本,定时将dump.rdb拷贝到其他机器
-
小时级备份脚本
// 创建两个目录 // 用于保存缓存文件 mkdir -p /var/redis/6379/cache // 用于保存脚本 mkdir -p /var/redis/6379/copy cd /var/redis/6379/copy创建按小时备份的脚本 vim redis_rdb_copy_hourly.sh
#!/bin/sh # 生成一个按小时的变量 作为备份的文件名 cur_date=`date +%Y%m%d%k` rm -rf /var/redis/6379/cache/$cur_date mkdir -p /var/redis/6379/cache/$cur_date cp /var/redis/6379/data/dump.rdb /var/redis/6379/cache/$cur_date # 删除48小时前的备份 del_date=`date -d -48hour +%Y%m%d%k` rm -rf /var/redis/6379/cache/$del_date配置定时任务,按小时执行
crontab -e // 添加以下配置 0 * * * * sh /var/redis/6379/copy/redis_rdb_copy_hourly.sh手动执行查看效果
sh /var/redis/6379/copy/redis_rdb_copy_hourly.sh cd /var/redis/6379/cache/ ll // 发现已经成功执行并备份了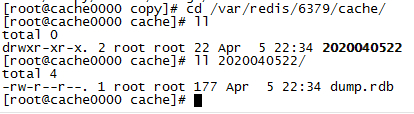
模拟容灾演练
基于纯RDB的容灾
-
测试未持久化数据丢失的情况
// 默认情况下 持久化的第一个检查点在5分钟,因此我们保存数据之后通过kill -9 暴力杀死进程 redis-cli set a 1 set b 2 get a get b // shutdown会自动做数据持久化并优雅关闭 redis-cli shutdown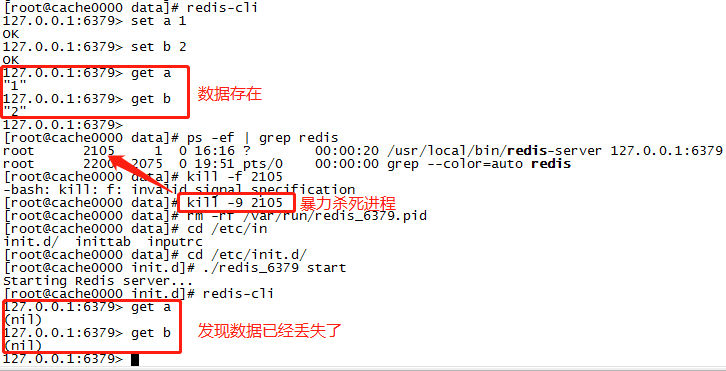
-
测试持久化之后的数据恢复
// 修改redis配置文件 vim /etc/redis/6379.conf // 配置一个5秒有1条数据发送变化就做持久化的策略 save 5 1 // 重启redis redis-cli shutdown cd /etc/init.d ./redis_6379 start //做上面相关的测试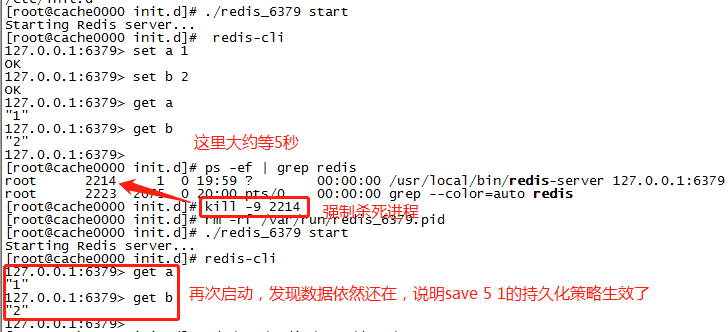
基于AOF+RDB的容灾演练
当我们开启了AOF+RDB,在数据恢复的时候,默认使用的AOF进行
// 当我们执行插入一个c=3的key
set c 3
// 查看aof文件,发现已经保存了相关的日志
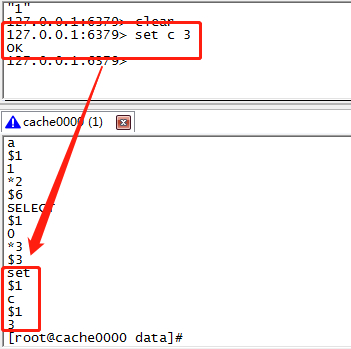
再次启动,发现数据依然存在
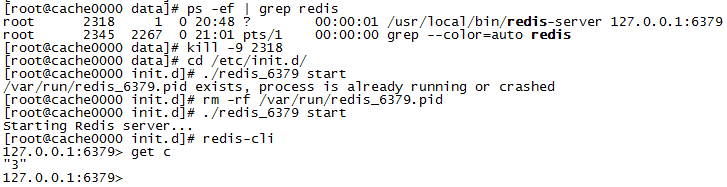
基于AOF+RDB数据回滚恢复
回滚数据的操作和存在数据中途开启AOF的操作几乎相关
- 第一步,将redis服务关闭
redis-cli shutdown
- 第二步,关闭AOF 将redis.conf
appendonly no
- 第三步,找到要恢复的dump.rdb冷备文件 将起拷贝到数据保存目录
- 第四步,备份最新aof配置文件(防止后续的操作失败,还可以基于它恢复)
- 第五步,启动redis服务并通过redis-cli连接服务
- 第六步,通过设置临时参数开启aof
config set appendonly yes
// 确保基于最新的redis数据成功了appendonly.aof文件
- 第七步,修改配置文件,开启AOF
appendonly yes
- 重启redis
redis-cli
cd /etc/init.d
./redis_6379 start
误删数据的容灾恢复
-
第一步,模拟删除数据
FLUSHDB -
第二步,防止rewrite,第一时间关闭Redis
redis-cli shutdown -
第三步,查看aof日志文件
// 保存持久化文件的目录 cd /var/redis/6379/data vim appendonly.aof // 删掉最后的 FLUSHDB指令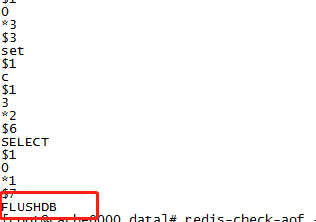
-
第四步,防止文件有问题,修复一下
redis-check-aof appendonly.aof
-
重启redis
redis-cli get a // 发现数据已经恢复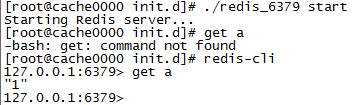
码字不易,感谢您的点赞!关注!评论!!!
标题:并发编程之Redis(二):Redis数据持久化及故障恢复方案
作者:码霸霸
地址:https://blog.lupf.cn/articles/2020/04/17/1587094544589.html