 IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
并发(七)之分布式异步更新:Zookeeper+Kafka实现数据分布式异步更新

集群安装说明
优先配置完单台机器的所有配置,并确定没有问题之后,将单机上的所有环境拷贝至其他机器,然后将其他机器个性化的配置修改后启动几个完成整个集群的安装
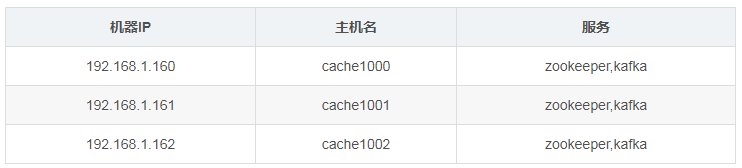
- 机器说明
jdk安装
-
安装
tar -zxvf jdk-8u241-linux-x64.tar.gz mv jdk1.8.0_241/ /usr/local/jdk1.8.0_241 // 配置环境变量 vi ~/.bash_profile // 添加以下配置 export JAVA_HOME=/usr/local/jdk1.8.0_241 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin // 刷新环境变量 source ~/.bash_profile // 测试配置 java -version
-
其他机器的部署
// 通过以下的直接,将JDK分别拷贝到其他的各台机器 scp -r /usr/local/jdk1.8.0_241/ root@cache1001:/usr/local/jdk1.8.0_241/ scp -r ~/.bash_profile root@cache1001:~/.bash_profile // 在每台机器都刷新一下环境变量 source ~/.bash_profile // 确认配置无误 java -version
Zookeeper
-
下载解压
cd /usr/local/src wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.5/zookeeper-3.4.5.tar.gz tar -zxvf zookeeper-3.4.5.tar.gz mv zookeeper-3.4.5 /usr/local/zookeeper -
配置环境变量
// 编辑环境变量配置 vi ~/.bash_profile export ZOOKEEPER_HOME=/usr/local/zookeeper PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$SCALA_HOME/bin:$ZOOKEEPER_HOME/bin // 刷新环境变量 source ~/.bash_profile -
修改配置
mkdir -p /var/zookeeper/data cd /usr/local/zookeeper/conf cp zoo_sample.cfg zoo.cfg // 修改配置 vim zoo.cfg // 修改数据缓存的地址 dataDir=/var/zookeeper/data // 添加以下集群配置 其中cache1000为主机名 server.0=cache1000:2888:3888 server.1=cache1001:2888:3888 server.2=cache1002:2888:3888 -
添加集群ID
cd /var/zookeeper/data vi myid // 添加 0 // 其他两台机器分别设置 1和2 -
启动
// 启动 zkServer.sh start // 查看状态 zkServer.sh status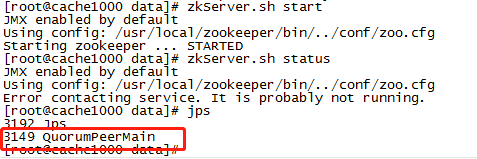
-
其他机器安装
// 通过这条指令将zk的包拷贝到各个机器 scp -r /usr/local/zookeeper/ root@cache1001:/usr/local/zookeeper/ // 拷贝环境变量并刷新 scp -r ~/.bash_profile root@cache1001:~/.bash_profile source ~/.bash_profile //创建数据目录 mkdir -p /var/zookeeper/data // 修改本机的id cd /var/zookeeper/data vi myid // 分别设置1和2 // 启动并查看状态 // 启动 zkServer.sh start // 查看状态 zkServer.sh status // 状态会出现2个follower和一个leader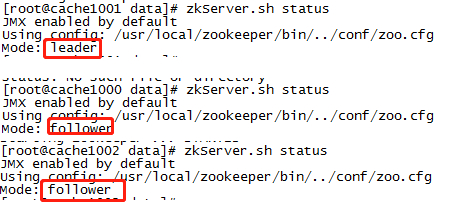
安装scala
-
下载解压
cd /usr/local/src wget https://downloads.lightbend.com/scala/2.12.11/scala-2.12.11.tgz tar -zxvf scala-2.12.11.tgz cd /usr/local/src mv scala-2.12.11 /usr/local/scala -
配置
// 编辑环境变量配置 vi ~/.bash_profile // 配置环境变量 export SCALA_HOME=/usr/local/scala PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$SCALA_HOME/bin // 刷新环境变量 source ~/.bash_profile // 测试 scala -version
-
其他机器的安装
// 通过以下指令将scala的包拷贝到各个机器 scp -r /usr/local/scala/ root@cache1001:/usr/local/scala/ // 拷贝环境变量并刷新 scp -r ~/.bash_profile root@cache1001:~/.bash_profile source ~/.bash_profile // 测试 scala -version
Kafka安装
-
下载
cd /usr/local/src/ wget https://downloads.apache.org/kafka/2.4.1/kafka_2.12-2.4.1.tgz tar -zxvf kafka_2.12-2.4.1.tgz mv kafka_2.12-2.4.1 /usr/local/kafka mkdir -p /var/kafka/log -
修改配置
vi /usr/local/kafka/config/server.properties // 依次增长的整数0 1 2 3 集群中Broker的唯一id broker.id:0 // 配置zookeeper的配置 zookeeper.connect=cache1000:2181,cache1001:2181,cache1002:2181 // 设置当前主机的IP advertised.host.name = 192.168.1.160 // 日志存储的路径 可以不设置,默认在:/tmp/kafka-logs/ 路径下 log.dirs=/var/kafka/log -
其他机器
// 将安装包分别拷贝到各自的机器 scp -r /usr/local/kafka/ root@cache1002:/usr/local/kafka/ // 各自修改配置 vim /usr/local/kafka/config/server.properties // 将broker.id修改为递增的唯一id;如1和2 -
启动服务
cd /usr/local/kafka/ bin/kafka-server-start.sh -daemon config/server.properties // nohup bin/kafka-server-start.sh config/server.properties & // bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 & -
测试
cd /usr/local/kafka/ // 创建一个test的topic bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --topic test --replication-factor 1 --partitions 1 --create // 删除topic bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --delete --topic test_topic // 查看topic列表 bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --list // 查看一个topic的东西 bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --topic test --describe // 启动一个消息生产者 bin/kafka-console-producer.sh --broker-list cache1000:9092,cache1001:9092,cache1002:9092 --topic test // 启动一个消息消费者 // 此方式是从latest的位置进行消费,之前的消息忽略掉 bin/kafka-console-consumer.sh --bootstrap-server cache1000:9092,cache1001:9092,cache1002:9092 --topic test // 启动一个从头开始消费的consumer bin/kafka-console-consumer.sh --bootstrap-server cache1000:9092,cache1001:9092,cache1002:9092 --from-beginning --topic test // 启动一个显示key的消费者 bin/kafka-console-consumer.sh --bootstrap-server cache1000:9092,cache1001:9092,cache1002:9092 --property print.key=true --topic test bin/kafka-consumer-groups.sh --bootstrap-server cache1000:9092,cache1001:9092,cache1002:9092 --describe --group test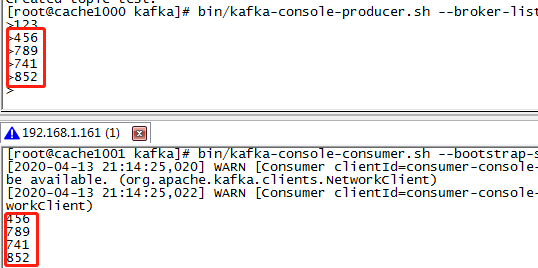
-
broker.id错误一
ERROR [KafkaServer id=1] Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer) // 原因是因为broker.id 设置重复 // 解决方式 // 修改server.properties下的broker.id保证其唯一 -
broker.id错误二
Configured broker.id 2 doesn't match stored broker.id 1 in meta.properties. If you moved your data, make sure your configured broker.id matches. If you intend to create a new broker, you should remove all data in your data directories (log.dirs).
// 该问题也就是上面的broker.id错误导致的元数据错误
// 在log.dirs(未配置默认在/tmp/kafka-logs/)目录下找到meta.properties
// 将其中broker.id设置为和上面的一致
SpringCloud整合Kafka
-
加入依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zookeeper-discovery</artifactId> </dependency> -
application.yml添加zookeeper的配置
spring: cloud: zookeeper: connect-string: 192.168.1.208:22181 # 集群地址用,隔开 discovery: instance-host: ${spring.cloud.client.ip-address} -
application.yml添加kafka的配置
spring: kafka: # 以逗号分隔的地址列表,用于建立与Kafka集群的初始连接(kafka 默认的端口号为9092) bootstrap-servers: 192.168.1.160:9092,192.168.1.161:9092,192.168.1.162:9092 producer: # 发生错误后,消息重发的次数。 retries: 0 #当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。 batch-size: 16384 # 设置生产者内存缓冲区的大小。 buffer-memory: 33554432 # 键的序列化方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer # 值的序列化方式 value-serializer: org.apache.kafka.common.serialization.StringSerializer # acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。 # acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。 # acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。 acks: 1 consumer: # 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D auto-commit-interval: 1S # 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理: # latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录) # earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录 auto-offset-reset: earliest # 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量 enable-auto-commit: false # 键的反序列化方式 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 值的反序列化方式 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer listener: # 在侦听器容器中运行的线程数。 concurrency: 5 #listner负责ack,每调用一次,就立即commit ack-mode: manual_immediate -
创建consumer
// groupId 消费组,必须指定 // topics 指定的主题 @Slf4j @Component public class KafkaProductInfoConsumer { /** * @param record * @param topic * @param consumer * @param ack */ @KafkaListener(groupId = KafkaConstant.GROUP_ID_SHOP_DATA_INIT, topics = KafkaConstant.TOPIC_PRODUCT_INFO_UPDATE) public void productInfoUpdate(ConsumerRecord<String, Object> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic, Consumer consumer, Acknowledgment ack) { if (null != record.value()) { String va = record.value().toString(); log.info("消费消息,topic= {} ,content = {}", topic, va); log.info("consumer content = {}", consumer); } ack.acknowledge(); }
zookeeper分布式锁
-
线程池
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * 数据修改的线程 */ public class DataInitThreadPool { /** * 指定数量的线程池 */ private ExecutorService executors = Executors.newFixedThreadPool(50); private DataInitThreadPool() { } /** * 静态内部类 */ static class Singleton { private static DataInitThreadPool dataUpdateThreadPool; static { dataUpdateThreadPool = new DataInitThreadPool(); } private static DataInitThreadPool getInstance() { return dataUpdateThreadPool; } } /** * 提交任务 * * @param thread */ public void submit(Thread thread) { executors.submit(thread); } /** * 获取单例 * * @return */ public static DataInitThreadPool getInstance() { return Singleton.getInstance(); } public static void init() { getInstance(); } } -
分布式锁工具类ZKUtils
import com.lupf.shopdatainit.thread.DataInitThreadPool; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.StringUtils; import org.apache.zookeeper.*; import java.util.concurrent.CountDownLatch; @Slf4j public class ZKUtils { // 单例对象 private static ZKUtils zkUtils; // zk的连接对象 private ZooKeeper zooKeeper; // 用于等待连接成功的countDownLatch private static CountDownLatch countDownLatch; // 默认的连接地址,可以在init()方法中指定 private static String connectString = "192.168.1.160:2181,192.168.1.161:2181,192.168.1.162:2181"; // 调用init方法是异步连接zk还是同步 // 默认是异步 private static boolean asynConnect = true; private ZKUtils(String connectString) { try { // 如果是同步连接zk if (!asynConnect) { // 初始化CountDownLatch countDownLatch = new CountDownLatch(1); } String cs = this.connectString; if (StringUtils.isNotBlank(connectString)) { cs = connectString; } // 创建线程连接zk DataInitThreadPool为线程池 DataInitThreadPool.getInstance().submit(new Thread(new ConnectThread(cs))); // 如果是同步连接 if (!asynConnect && null != countDownLatch) { log.info("zk sync connecting"); // 等待zk的连接成功 countDownLatch.await(); log.info("zk sync connected"); } else { log.info("zk asyn connecting"); } } catch (InterruptedException e) { e.printStackTrace(); } } /** * 连接zk的线程 */ private class ConnectThread implements Runnable { // 连接地址 private String connectString; public ConnectThread(String connectString) { this.connectString = connectString; } @Override public void run() { connect(); } private void connect() { // 设置个死循环 如果连接不成功 就一直狂连 while (true) { try { // 创建连接对象 zooKeeper = new ZooKeeper(connectString // 地址 , 30000 // 超时时间 , new ZookeeperWatcher()); //监听器 break; } catch (Exception e) { e.printStackTrace(); } try { // 如果连接失败了 等半秒钟再次尝试 Thread.sleep(500); } catch (InterruptedException e) { } } } } private class ZookeeperWatcher implements Watcher { @Override public void process(WatchedEvent watchedEvent) { Event.KeeperState state = watchedEvent.getState(); if (Event.KeeperState.SyncConnected == state) { // zk连接成功 if (!asynConnect && null != countDownLatch) { // 计数减一 countDownLatch.countDown(); } log.info("zk连接成功!!!!"); } else if (Event.KeeperState.Disconnected == state) { log.info("zk连接断开!!!!"); zooKeeper = null; } } } public static ZKUtils getInstance() { if (null == zkUtils) { synchronized (ZKUtils.class) { if (null == zkUtils) { zkUtils = new ZKUtils(connectString); } } } return zkUtils; } /** * 项目启动时 初始化 * * @param cs 连接的地址 * @param asyn_connect 是否异步连接 true:异步,false:同步(只有连接成功了方法才会执行完) */ public static void init(String cs, boolean asyn_connect) { if (StringUtils.isNotBlank(cs)) { connectString = cs; } // 移除创建连接,初始化的时候不等待 asynConnect = asyn_connect; getInstance(); } //------------------------------------------------------------------------------ /** * 获取锁 * * @param path 创建的临时节点的路径 * @param waitTime 超时时间 如果超过这个时间还没有获取到锁,就直接返回 -1表示不超时 * @return true 获取锁成功 false失败 */ public boolean acquireDistributedLock(String path, long waitTime) { long time = System.currentTimeMillis(); int count = 0; while (true) { count++; if (null != zooKeeper) { try { // log.info("线程ID:{}第{}次尝试获取:{}的锁!", Thread.currentThread().getId(), count, path); // 创建一个临时的节点 zooKeeper.create(path, "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); // 创建成功说明获取锁成功 log.info("线程ID:{}第{}次尝试成功获取:{}的锁!", Thread.currentThread().getId(), count, path); return true; } catch (Exception e) { //e.printStackTrace(); // log.error("线程ID:{}第{}次尝试获取:{}的锁失败!", Thread.currentThread().getId(), count, path); } } else { // zk尚未初始化成功!等待初始化.... } if (waitTime > 0) { long now = System.currentTimeMillis(); if (now - time > waitTime) { log.info("尝试获取了{}次锁失败,超时....", count); break; } } // 到这里说明创建节点失败,需要重试 try { // 等20毫秒再去那锁 Thread.sleep(20); } catch (InterruptedException e) { } } return false; } /** * 释放锁 * * @param path 释放的路径 */ public void releaseDistributedLock(String path) { try { // 直接删掉临时节点 zooKeeper.delete(path, -1); } catch (Exception e) { e.printStackTrace(); } } }
- 基于商品ID的分布式锁
public class ProductLockUtils
{
private static final String PRODUCT_LOCK_PROFIX = "/product_lock_";
private ProductLockUtils()
{
}
static class Singleton
{
private static ProductLockUtils productLockUtils;
static
{
productLockUtils = new ProductLockUtils();
}
public static ProductLockUtils getInstance()
{
return productLockUtils;
}
}
public static ProductLockUtils getInstance()
{
return Singleton.getInstance();
}
/**
* 加锁
*
* @param producuId 商品ID
* @param waitTime 超时时间
* @return
*/
public boolean acquireDistributedLockByProductId(Integer producuId, long waitTime)
{
String path = PRODUCT_LOCK_PROFIX + producuId;
return ZKUtils.getInstance().acquireDistributedLock(path, waitTime);
}
/**
* 释放锁
*
* @param producuId 商品ID
*/
public void releaseDistributedLockByProductId(Integer producuId)
{
String path = PRODUCT_LOCK_PROFIX + producuId;
ZKUtils.getInstance().releaseDistributedLock(path);
}
}
- DB修改之后,如何及时更新缓存数据
- 管理服务或业务服务更新数据并将数据保存到了DB
- 管理平台或业务服务添加商品已经修改的消息至kafka
- 数据初始化服务收到kafka消息,此时可能有大量的某个商品的修改
- 数据初始化服务通过ZK拿到某个商品的分布式锁
- 查询Redis中是否存在了缓存数据;没有就直接保存;如果有且更新时间早于最新的一次修改,更新缓存,否则跳过
- 更新完之后,释放ZK的锁
标题:并发(七)之分布式异步更新:Zookeeper+Kafka实现数据分布式异步更新
作者:码霸霸
地址:https://blog.lupf.cn/articles/2020/04/17/1587096190497.html