IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
HashMap的这个小'坑',老司机也可能翻车

大家好,我是一航;
昨天一位粉丝朋友和我聊天,说遇到了一个莫名奇妙的问题,让我帮着分析一下;经过他的一轮描述,发现是一个HashMap元素顺序小'坑';但是一不留神,老司机也容易在这里翻车。
一句话来描述一下他的问题:明明我数据库语句使用了Order by进行了排序,日志中也看到数据是按顺序查出来了,但业务层收到数据依然还是乱序的呢?;
整个过程,确实出现了好几处的迷惑现象,影响了他对问题的判断;下面就从一个小案例加上源码分析,来看看到底发生了什么。
问题复现
为了方便说明问题,这里用一个简单的业务场景来模拟一下;
数据表
一张简单的学生信息表
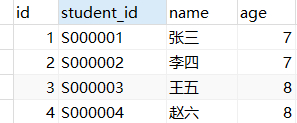
需求
需要按id顺序(order by id)获取出学号(student_id)对应的学生信息;为了方便业务层面根据学号获取数据,这位朋友采用了如下的数据格式,并用了HashMap在业务代码中接收数据:
{
"S000001": {
"name": "张三",
"student_id": "S000001",
"age": 7
},
"S000002": {
"name": "李四",
"student_id": "S000002",
"age": 7
},
"S000003": {
"name": "王五",
"student_id": "S000003",
"age": 8
},
"S000004": {
"name": "赵六",
"student_id": "S000004",
"age": 8
}
}
代码实现
-
Dao
@MapKey("student_id") HashMap<String, Object> getStudentId(); -
xml
<select id="getStudentMap" resultType="java.util.HashMap"> select student_id , `name` , age from student_info order by id </select> -
测试用例
@Autowired StudentInfoMapper studentInfoMapper; @Test void map() { HashMap<String, Object> studentId = studentInfoMapper.getStudentMap(); studentId.forEach((id, studentInfo) -> log.info("学号:{} 信息:{}", id, JSON.toJSONString(studentInfo))); }
问题点
以上代码的执行日志;
当学号是如下数据再查询的时候,整个数据查询和使用都是没有任何问题的
==> Preparing: select student_id , `name` , age from student_info order by id
==> Parameters:
<== Columns: student_id, name, age
<== Row: S000001, 张三, 7
<== Row: S000002, 李四, 7
<== Row: S000003, 王五, 8
<== Row: S000004, 赵六, 8
<== Total: 4
Closing non transactional SqlSession
StudentTest : 学号:S000001 信息:{"name":"张三","student_id":"S000001","age":7}
StudentTest : 学号:S000002 信息:{"name":"李四","student_id":"S000002","age":7}
StudentTest : 学号:S000003 信息:{"name":"王五","student_id":"S000003","age":8}
StudentTest : 学号:S000004 信息:{"name":"赵六","student_id":"S000004","age":8}
但是当把学号换成以下数据之后:
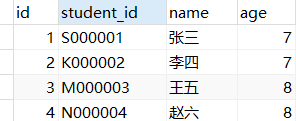
根据查询结果和输出日志可以看到,数据库查询出来的数据是顺序的;但是返回到业务层的HashMap中的数据就变成无序的了;
==> Preparing: select student_id , `name` , age from student_info order by id
==> Parameters:
<== Columns: student_id, name, age
<== Row: S000001, 张三, 7
<== Row: K000002, 李四, 7
<== Row: M000003, 王五, 8
<== Row: N000004, 赵六, 8
<== Total: 4
Closing non transactional SqlSession
StudentTest : 学号:M000003 信息:{"name":"王五","student_id":"M000003","age":8}
StudentTest : 学号:K000002 信息:{"name":"李四","student_id":"K000002","age":7}
StudentTest : 学号:N000004 信息:{"name":"赵六","student_id":"N000004","age":8}
StudentTest : 学号:S000001 信息:{"name":"张三","student_id":"S000001","age":7}
明明前面查询出来是正常的,咋换了个数据就不正常呢?原因只是前面的那批数据碰巧是对的而已,不要被表象给迷惑了,实际上两组数据这样返回都是不对的。
而实际的业务Bug中,往往也会因为这些迷惑数据(A用户访问正常,B用户访问就不正常了),导致一度怀疑人生...
问题分析
既然数据库的日志是顺序的获取出了数据,说明SQL层面是没有问题的,那问题点肯定是出在了HashMap;了解HashMap都知道,HashMap本身是无序的,但最让很多新手朋友疑惑的是,你无序没关系,但我是插入的时候是按我需要的顺序插入,这难道不行?如果你疑惑的是这个点,那说明你还没有理解这个无序的意思;HashMap的插入顺序和迭代取出顺序是没有任何关系的;
除非你在获取的时候,已知了插入时的所有key且都保存了下来;就可以按这个顺序key去获取;但实际的使用过程,很少会出现这么使用的情况;
简单的插入、获取示例:
public static void t1() {
HashMap<String, Object> map = new HashMap<>();
for (int i = 0; i < 5; i++) {
String k = "key:" + i;
String v = "va" + i;
map.put(k, v);
log.info("顺序插入 key:{} <-- va:{}", k, v);
}
log.info("-----------------------------");
map.forEach((k, v) -> log.info("迭代获取 key:{} --> va:{}", k, v));
}
执行日志:
Main - 顺序插入 key:key:0 <-- va:va0
Main - 顺序插入 key:key:1 <-- va:va1
Main - 顺序插入 key:key:2 <-- va:va2
Main - 顺序插入 key:key:3 <-- va:va3
Main - 顺序插入 key:key:4 <-- va:va4
Main - -----------------------------
Main - 迭代获取 key:key:2 --> va:va2
Main - 迭代获取 key:key:1 --> va:va1
Main - 迭代获取 key:key:0 --> va:va0
Main - 迭代获取 key:key:4 --> va:va4
Main - 迭代获取 key:key:3 --> va:va3
源码原因分析
接下来就从源码的角度来详细的说一说HashMap的无序到底是怎么回事!
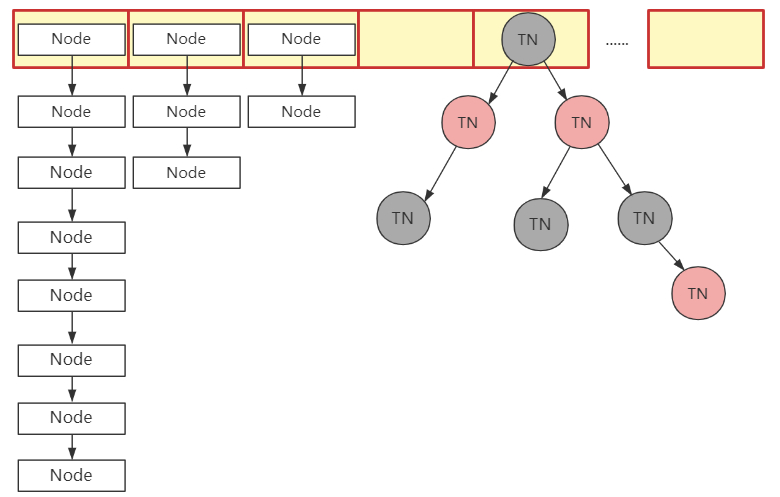
HashMap的数据结构
Java8 HashMap的数据结构如下图;采用的是数组+联表+红黑树的方式;因此元素所处的数组(黄色区域)下标位置是通过(n - 1) & hash])来定位的,当如果出现不同key的hash值相同时,就会将同下标的值以联表或者红黑树的方式存起来;
HashMap的插入过程
-
根据key的hash值和数组长度的与运算定位数组下标
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { //... }关键代码
(n - 1) & hash]),其中n为数组的长度,hash值是通过hash(key)运算得来 -
tab[i]下标i的值为null时,就直接实例化放在下标位置
也就是上面的
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); -
如果出现hash冲突,tab[i]已经有值了,就会以链表方式跟在Node后面
-
联表中key存在了
修改值
-
当
if ((e = p.next) == null)下一个节点为空的时候就实例化一个新的Node,跟在后面
// .... else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } }
-
-
如果联表的长度大于8个的时候,就会转换为红黑树的结构存储
经过上面4个步骤,元素并没有按顺序存储,而是被打散在数组的各个下标下面;链表或红黑树的元素位置也没有固定顺序;同一hash的key,插入的时机不同,所处的位置也就不同;
示例数据保存分析
有了源码分析的支持,下面就来详细的看一下保存在hashMap中的key、value在使用(n - 1) & hash])计算之后的下标位置:
| key | value | 数组下标i = (n - 1) & hash]) |
|---|---|---|
| key:0 | va0 | 6 |
| key:1 | va1 | 5 |
| key:2 | va2 | 4 |
| key:3 | va3 | 11 |
| key:4 | va4 | 10 |
最终key、value分布情况:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| key | key:2 | key:1 | key:0 | key:4 | key:3 | ||||||||
| 值1 | va2 | va1 | va0 | va4 | va3 | ||||||||
| 值2 |
迭代获取
HashMap元素的迭代获取,就是先从左到右遍历数组,当数组索引位置有值时,再从上往下遍历联表或者红黑树;
源码如下:
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key, e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
核心代码
第一个循环for (int i = 0; i < tab.length; ++i):左到右遍历数组
第二个循环for (Node<K,V> e = tab[i]; e != null; e = e.next):从上往下遍历联表或者红黑树
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key, e.value);
}
对着前面key、value分布情况表格,再来回看输出日志,就能明白,为啥迭代出来是下面这样的输出结果了
Main - 获取 key:key:2 --> va:va2
Main - 获取 key:key:1 --> va:va1
Main - 获取 key:key:0 --> va:va0
Main - 获取 key:key:4 --> va:va4
Main - 获取 key:key:3 --> va:va3
有序问题如何解决
当需要保证插入顺序和获取顺序一致时,可以采取有序的数据结构来保存数据,如List,LinkedHashMap等...
MyBatis数据查询
例如一开始列举的示例;当数据查询需要按顺序返回时,可以变换一下方式,采用List接收数据;如果业务真的需要通过Map参与,可以通过转换,来重新构造一个LinkedHashMap的有序数据结构用于业务逻辑的需要;
示例如下:
-
dao
List<StudentInfo> getStudentList(); -
xml
<select id="getStudentList" resultType="com.ehang.springboot.mybatisplus.generator.student.demain.StudentInfo"> select student_id , `name` , age from student_info order by id </select> -
test
@Autowired StudentInfoMapper studentInfoMapper; @Test void list() { List<StudentInfo> studentList = studentInfoMapper.getStudentList(); studentList.forEach(studentInfo -> log.info("{}", JSON.toJSONString(studentInfo))); }测试输出
==> Preparing: select student_id , `name` , age from student_info order by id ==> Parameters: <== Columns: student_id, name, age <== Row: S000001, 张三, 7 <== Row: S000002, 李四, 7 <== Row: S000003, 王五, 8 <== Row: S000004, 赵六, 8 <== Total: 4 Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@ae5fa7] StudentTest : {"age":7,"name":"张三","studentId":"S000001"} StudentTest : {"age":7,"name":"李四","studentId":"S000002"} StudentTest : {"age":8,"name":"王五","studentId":"S000003"} StudentTest : {"age":8,"name":"赵六","studentId":"S000004"}
LinkedHashMap
-
简介
当Map需要有序时,也只需将HashMap换成LinkedHashMap即可保证插入和取出的顺序一致;
LinkedHashMap是HashMap的子类
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> { //.... }因此LinkedHashMap拥有了HashMap的所有功能;但是LinkedHashMap采用的是双向联表的方式保存数据;因此就能保证数据保存顺序和读取顺序的一致性
以下是读取数据的源码;可以看出是有序的遍历了整个联表;
public void forEach(BiConsumer<? super K, ? super V> action) { if (action == null) throw new NullPointerException(); int mc = modCount; for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) action.accept(e.key, e.value); if (modCount != mc) throw new ConcurrentModificationException(); } -
测试示例改造:
public static void t1() { HashMap<String, Object> map = new LinkedHashMap<>(); for (int i = 0; i < 5; i++) { String k = "key:" + i; String v = "va" + i; map.put(k, v); log.info("插入 key:{} <-- va:{}", k, v); } log.info("-----------------------------"); map.forEach((k, v) -> log.info("获取 key:{} --> va:{}", k, v)); }输出:
Main - 插入 key:key:0 <-- va:va0 Main - 插入 key:key:1 <-- va:va1 Main - 插入 key:key:2 <-- va:va2 Main - 插入 key:key:3 <-- va:va3 Main - 插入 key:key:4 <-- va:va4 Main - ----------------------------- Main - 获取 key:key:0 --> va:va0 Main - 获取 key:key:1 --> va:va1 Main - 获取 key:key:2 --> va:va2 Main - 获取 key:key:3 --> va:va3 Main - 获取 key:key:4 --> va:va4
总结
每一种数据结构,都有他其独有的特性;因此,基础知识的部分,一定要将差异部分的原理了解清楚,只要这样,在遇到问题的时候,才能准确分析出问题的本质,否则很容易被表象,被日志给迷惑而陷入迷茫;
好了,今天的分享就到这里,不介意的话,三连给安排一下!感激不尽!