IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
一行代码跑一天的Bug会不会写?不会我教你啊!

大家好,我是一航!
前两天,因为一个没有经过深思熟虑的建议,让一位粉丝朋友写的一行代码,足足跑了一下午还没跑完,深感内疚;而且这个问题在实际的开发中也很容易遇到,且很难发现,今天来反思总结一下;
起因是这样:
一粉丝朋友微信问我,说他现在有个需求,就是有一些新闻资讯类的稿件(一段很长的字符串文本),然后他需要查找一些特定的文本段落是否在这个稿件中存在;初听是文本匹配的事儿,仔细想来,也确实是文本匹配的事儿(听君一席话,胜似一席话);
简单示例说:
稿件:据北京气象局报道,——2022年3月x日,北京天气晴转多云,最高温度....
匹配段落 :
- 深圳、天气
- ——2022年3月x日,北京天气
要经过匹配得出,1没有在稿件中出现,2在稿件中出现了;
看到这个示例,大家都会觉得这有啥,但凡学了点Java的,都能轻松匹配出来;直接 String.indexOf找一下特定的字符是否存在不就完了;
但是让这位朋友给否定了,原因是原始稿件中的 标点符号、换行符、特殊符号规则和要匹配的文本中的可能不一致;也就是说,可能出现文本内容对的上,但标点等特殊符号不一致的情况,如果使用 String.indexOf,这种情况就查找不出来了;但是产品要求是,这种是符合要求的段落,需要匹配出来;
如此说来,需要做模糊匹配,很自然的就想到了:正则表达式;因为一切需求,都只是这位朋友在微信传达,简单想了想,既然有特殊符号,那咱就把特殊符号转换成正则通配符,然后去匹配就完了;
交流想法之后,这位朋友也很快就明白了,然后就去写了相关的代码:
以下是后来基于他的实现,简写的一个demo
-
稿件:
据北京气象局报道,——2022年3月x日,北京天气晴转多云,最高温度.... -
匹配文本
——2022年3月x日,北京天气 -
正则表达式
将匹配文本中的特殊符号转换成通配符
(.*),最终得到的正则表达式如下:(.*)(.*)2022年3月x日(.*)北京天气 -
代码示例
public class RegetTest { public static void main(String[] args) { String news = "据北京气象局报道, ——2022年3月x日,北京天气晴转多云,最高温度...."; List<String> ts = new ArrayList<>(); ts.add("深圳、天气"); // 这里的,是因为英文格式的 ts.add("——2022年3月x日,北京天气"); // 替换换行符 String newsSpace = replaceTxt(news, "\\s*|\t|\r|\n", ""); System.out.println("原始稿件:" + newsSpace); for (String txt : ts) { // 替换标点符号 String regexSpace = replaceTxt(txt, "[\\pP\\pS\\pZ]", "(.*)"); System.out.println("匹配正则:" + regexSpace); //正则匹配 Pattern pattern = Pattern.compile(regexSpace); Matcher matcher = pattern.matcher(newsSpace); if (matcher.find()) { System.out.println(txt + "-->匹配上了"); } else { System.out.println(txt + "-->未匹配上了"); } } } /** * @param str 文本 * @param regex 正则 * @param replacement 替换符 * @return */ private static String replaceTxt(String str, String regex, String replacement) { Pattern p_space = Pattern.compile(regex, Pattern.CASE_INSENSITIVE); Matcher m_space = p_space.matcher(str); // 过滤空格回车标签 str = m_space.replaceAll(replacement); String regEx_space = "";//定义空格回车换行符 // 返回文本字符串 return str.trim(); } }运行结果
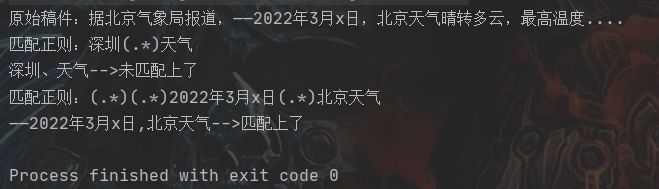
根据测试效果来看,似乎已经达到预期的效果了,速度也挺快的...
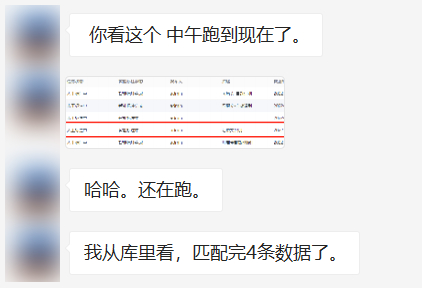
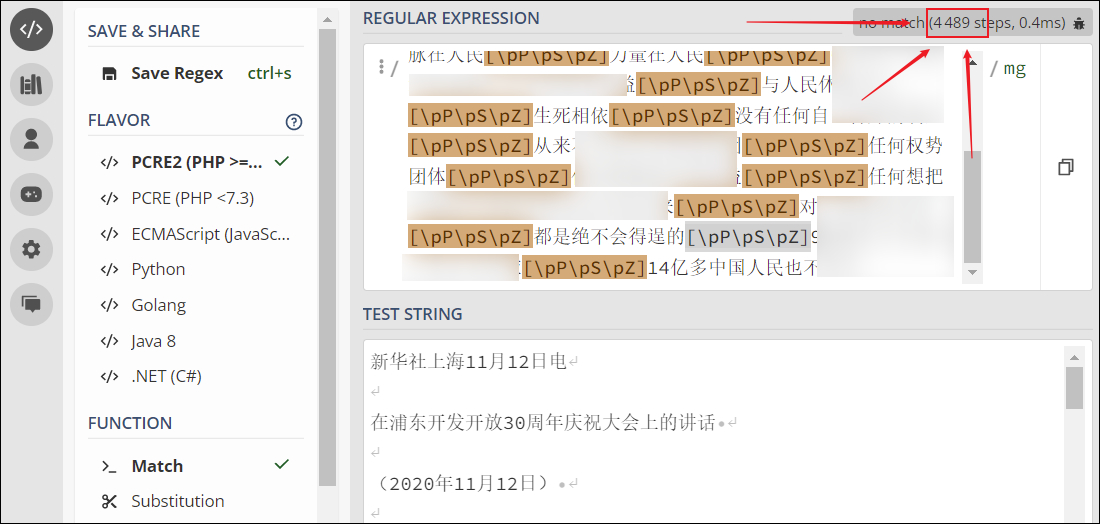
当发布到测试环境,跑真实的业务数据时,发现有的稿件匹配起来还可以,有的就非常的慢,慢到什么程度?就是文章开头的那张图,足足跑了一下午,才完成4个文本段的查找;很明显,这个方案不太对劲;
找这位朋友要了一个明显跑的慢的实测数据,运行了一下,结果CPU立马100%,电脑的风扇突然就狂叫了起来,一种久违的负重感扑面而来,因为太久没听到我电脑如此愤怒的咆哮了;不出意外地全部卡在了 matcher.find()这行代码;破案了,就是正则的问题,一切迹象表明,正则的匹配经历了大量的运算;
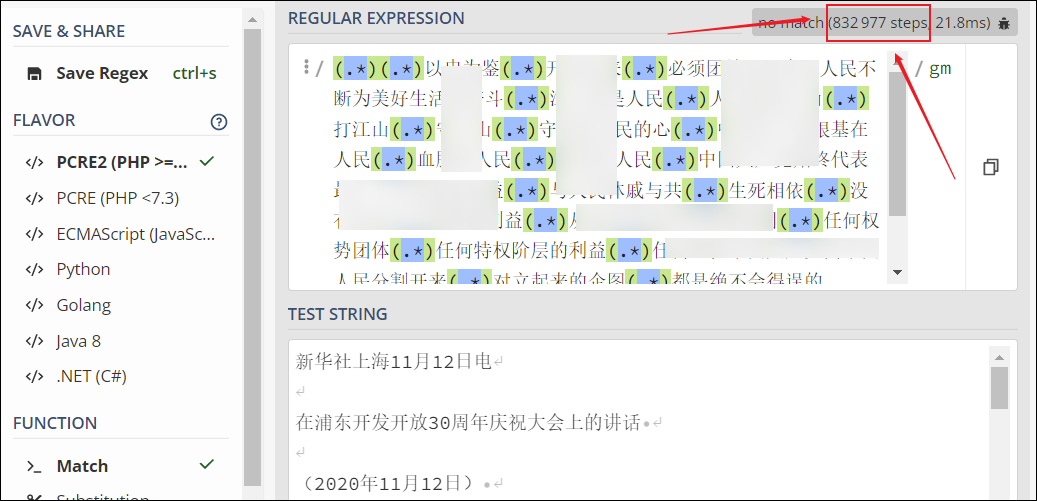
那是什么原因呢?再来细品生成的正则,全篇都是使用的 (.*)进行统配,我们完全忽略了一个很严重的问题:正则表达式的回溯陷阱
通过网站: https://regex101.com/ 验证了一下想法,果然不错所料,整个匹配过程高达83万个步骤,这能快到哪里去了;
既然排查到原因了,下面就来详细说一下什么是正则的回溯,以及如何解决这个问题;
正则表达式
在剖析回溯陷阱的之前,我们必须对正则表达式有一个较为深层次的了解;这里假定各位都已经掌握了正则的基本用法,下面所涉及到的正则知识点,也都只是与回溯相关的内容;如果没使用过,务必要学一下;实际开发中用正则做匹配的场景也非常的多,比如:电话号码,邮箱等固定规则的文本校验;用正则验证起来就非常的方便。
什么是正则表达式引擎
正则表达式是一个很实用的匹配符号,而且功能非常强大,因此就必须有一套算法来做支撑,那这个算法就叫做正则表达式引擎;其实现方式有两种:
-
DFA 自动机(Deterministic Final Automata 确定型有穷自动机)
特点:时间复杂度是线性的,更加稳定,但是功能有限。
-
NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)
复杂度比较不稳定,是好是坏,正则表达式的好坏直接关系着最后的执行的效率,但优势就是功能非常的强大;所以像Java 、.NET、Perl、Python、Ruby、PHP 等语言都是使用的这种方式来实现;
那NFA是如何进行匹配的呢?看示例:
String text = "Hello Java";
String regex = "Java";
NFA是基于正则表达式,逐一读取对应的字符,然后与文本中的字符串进行比较,匹配上就换下一个正则的字符,没匹配上就换下一个文本字符,直到结束;下面我们来拆解一下上面这个示例的匹配过程:
- 取出正则的第一个字符
J;然后与文本中的第一个字符H比较,发现没匹配上,就继续文本下一个字符e,还是没匹配上,继续下一个文本字符....;直到找到文本中的J,发现匹配上了; - 然后再取正则的第二个字符
a,文本会取第一步中匹配上的J后面的那个字符,也就是a,发现能和正则的字符a对上,继续下一个; - 再取正则的第三个字符
v;文本继续往后取v,能匹配上,继续下一个; - 再取正则的第四个字符
a;文本继续往后取a,能匹配上,正则字符已经匹配完,那么匹配结束,最终的结果是匹配成功。
数量(长度)匹配
上面的示例,列举了最基本的文本查找,但是实际使用的时候,一般并不是一个固定的串,而是一个规则;比如约束 长度、取值范围等。
例如:
String regex = "ab{1,3}c";
{1,3}用来约束前导字符 b最少出现1次,最多出现3次;
因此关于数量约束的表达式,一共有如下几种形式:
-
{m,n}告诉引擎匹配前导字符最少m次,最多n次;
如果
n省略;例:X{3,},则表示前导字符X最少要出现3次;如果
,n省略;例:X{3},则表示前导字符X只能出现3次; -
?告诉引擎匹配前导字符0次或一次。等价于:
X{0,1} -
+告诉引擎匹配前导字符1次或多次。等价于:
X{1,} -
*告诉引擎匹配前导字符0次或多次。等价于:
X{0,}
回溯陷阱
当需要匹配多个字符的时候,就可能出现回溯问题;
贪婪模式
如果单独使用上面介绍的四个数量表达式的时候,表达式引擎默认采用的贪婪模式进行匹配,在该模式下,正则引擎会 尽可能多的去匹配前导字符;
如下示例,结果是匹配成功
String txt = "abbc";
String regex = "ab{1,3}c";
详细步骤:
| 步骤 | 正则:ab{1,3}c | 文本:abbc | 是否匹配 |
|---|---|---|---|
| 第一步 | a | a | 是 |
| 第二步 | ab | ab | 是 |
| 第三步 | abb | abb | 是 |
| 第四步 | abbb | abbc | 否 |
| 第五步 | abb | abb(回溯) | 是 |
| 第六步 | abbc | abbc | 是 |
在第四步尽可能多的匹配前导字符数量时,发现文本匹配失败,因此触发了文本的回溯;
懒惰模式
当在数量表达式后面再加一个 ?则表示为懒惰模式,在该模式下,正则引擎 尽可能少的匹配前导字符;
如下示例,结果是匹配成功
String txt = "abbc";
String regex = "ab{1,3}?c";
| 步骤 | 正则:ab{1,3}c | 文本:abbc | 是否匹配 |
|---|---|---|---|
| 第一步 | a | a | 是 |
| 第二步 | ab | ab | 是 |
| 第三步 | abc | abb | 否 |
| 第四步 | ab(回溯) | ab | 是 |
| 第五步 | abb | abb | 是 |
| 第六步 | abbc | abbc | 是 |
在第三步尽可能少的匹配前导字符数量时,文本符合要求,但与正则不匹配,所以触发了正则部分的回溯;
独占模式
如果在数量表达式后加上一个加号(+),则会开启独占模式。同贪婪模式一样,独占模式一样会匹配最长。不过在独占模式下,正则表达式尽可能长地去匹配字符串,一旦匹配不成功就会结束匹配而不会回溯。
如下示例,结果是匹配失败
String txt = "abbbc";
String regex = "ab{1,3}+bc";
| 步骤 | 正则:ab{1,3}+bc | 文本:abbbc | 是否匹配 |
|---|---|---|---|
| 第一步 | a | a | 是 |
| 第二步 | abbb | abbb | 是 |
| 第三步 | abbbb | abbbc | 否 |
第二步中,正则 b{1,3}+会匹配最长,因此得到正则部分为 abbb,与文本 abbb比较,能匹配上;
第三步中,正则的下一个字符是 b,所以得到正则文本是 abbbb,而文本的下一个字符是 c,匹配失败;
由于独占模式不进行回溯,所以匹配结束;
三种模式的表达式差异
| 贪婪模式 | 懒惰模式 | 独占模式 |
|---|---|---|
| X? | X?? | X?+ |
| X* | X*? | X*+ |
| X+ | X+? | X++ |
| X{n} | X{n}? | X{n}+ |
| X{n,} | X{n,}? | X{n,}+ |
| X{n,m} | X{n,m}? | X{n,m}+ |
问题分析
现在,我们回到一开始我们遇到的问题,我们采用的是通过 (.*)去匹配标点符号,而 .并不止是匹配标点符号,而是能匹配除换行符外的任意字符,*代表着匹配数量可以 0-无数次;由于匹配文本是 --开头,导致替换后的正则就以两个 (.*)开头了,因为 (.*)可以匹配任意字符、任意长度;使得文本全文参与了多次回溯;
为了方便查看动图效果,下面的示例对段落进行了缩减,动图效果可以通过 https://regex101.com/ 查看全部的步骤过程
String txt = "新华社上海11月12日电";
String regex = "(.*)(.*)以史为鉴";
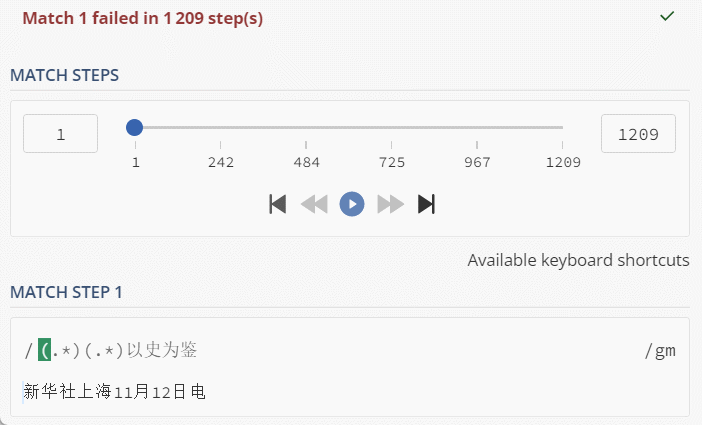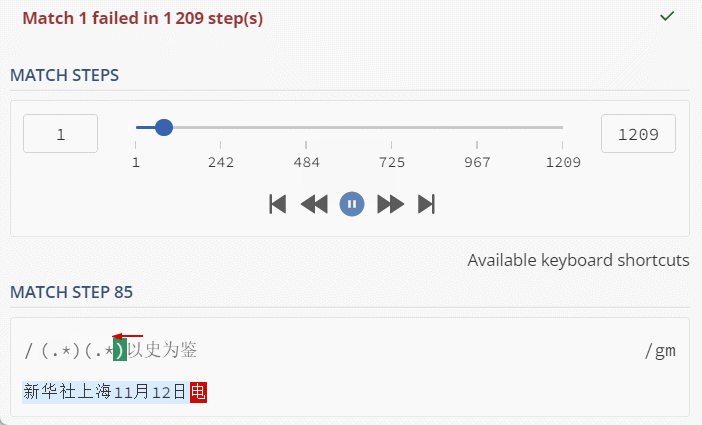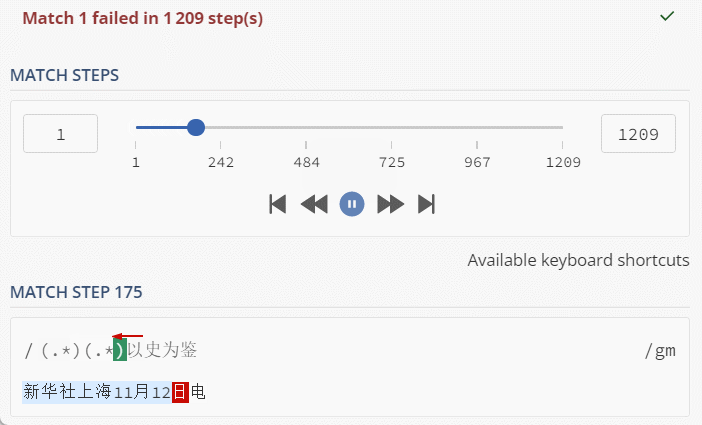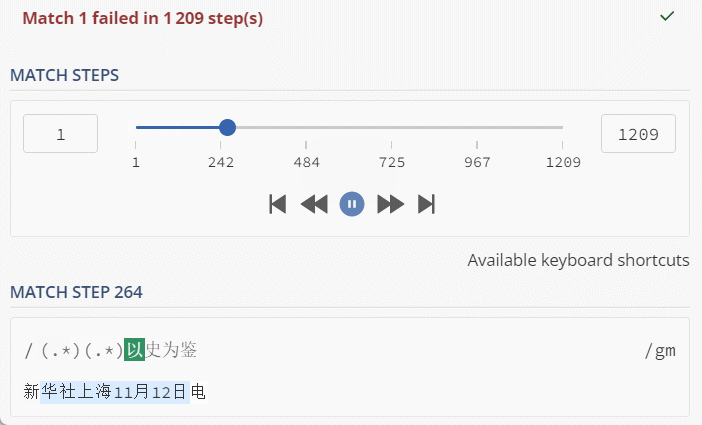
看到这里动图,是不是觉得还好,1000多步,对于计算机来说,小意思了;但是,也可以很容易的分析出,当匹配文本和正则文本变长,步骤会呈现出几何倍速增长;
这也就是文章开始遇到的问题,一段不是很长的文本,匹配步骤高达83万步,最终导致卡顿的原因了;
如何解决
优化正则
NFA算法的执行效率跟正则表达式的好坏有直接性的关系,那我们就可以通过优化正则来提高性能,减少回溯;
-
将贪婪模式转换为懒惰模式或者独占模式
虽然说转为懒惰模式并不会解决回溯问题,但是可以有效的减少会所的次数
-
能明确指定范围的,就不要使用统配
比如只需匹配
[abc]的,就不要使用[a-z];只需匹配标点符号的[\pP\pS\pZ],就不要使用通配符(.?) -
减小数量表达式的取值范围
能使用
?(0次或者1次)的就不要使用*(1次或者多次);能使用
{m,n}限定范围的就不要使用*(1次或者多次);
基于上面的优化思路,结合本文的案例,来思考一下如何优化:
一开始的方式通过 (.*)(0次-多次)来匹配标点符号,但这些统配符都是通过标点符号替换来的,所以完全不需要使用通配符,而是使用标点符号的表达式 [\pP\pS\pZ]来匹配即可,从而减少不必要的字符回溯;
经过验证,匹配的次数一下立马就从83万次降为4489次;性能足足提升了近200倍;
不用正则
避免回溯的最佳方法,就是不用正则;
其实一开始,整个实现思路就不是特别的对;虽然通过上面对正则的优化,把整个匹配速度提上来了,但是这并没有达到一个最优效果;
文章一开始放弃 String.indexOf方案是因为标点符号可能不一致,那我们完全可以把标点符号、换行符全部通过正则表达式剔除掉,再通过 indexOf进行文本查找,这样性能要比通过正则表达式匹配快上很多;
详细步骤:
-
第一步,通过正则表达式,剔除原始稿件中的特殊符号
-
第二步,通过正则表达式,剔除匹配文本中的特殊符号
-
第三步,通过
String.indexOf查找匹配文本是否在原始稿件中出现过 -
代码示例
public class RegetTest2 { public static void main(String[] args) { String news = "据北京气象局报道, ——2022年3月x日,北京天气晴转多云,最高温度...."; List<String> ts = new ArrayList<>(); ts.add("深圳、天气"); ts.add("——2022年3月x日,北京天气"); System.out.println("原始稿件:" + news); // 移除原始文本换行符 String newsSpace = replaceTxt(news, "\\s*|\t|\r|\n", ""); // 移除原始文本的特殊标点符号 newsSpace = replaceTxt(news, "[\\pP\\pS\\pZ]", ""); System.out.println("移除特殊符号的稿件:" + newsSpace); for (String txt : ts) { System.out.println(); // 移除匹配文本换行符 String regexSpace = replaceTxt(txt, "\\s*|\t|\r|\n", ""); // 移除匹配文本的特殊标点符号 regexSpace = replaceTxt(txt, "[\\pP\\pS\\pZ]", ""); System.out.println("查找文本:" + txt); if (newsSpace.indexOf(regexSpace) >= 0) { System.out.println("通过:"+regexSpace + "-->匹配上了"); } else { System.out.println("通过:"+regexSpace + "-->未匹配上了"); } } } /** * @param str 文本 * @param regex 正则 * @param replacement 替换符 * @return */ private static String replaceTxt(String str, String regex, String replacement) { Pattern p_space = Pattern.compile(regex, Pattern.CASE_INSENSITIVE); Matcher m_space = p_space.matcher(str); // 过滤空格回车标签 str = m_space.replaceAll(replacement); // 返回文本字符串 return str.trim(); } }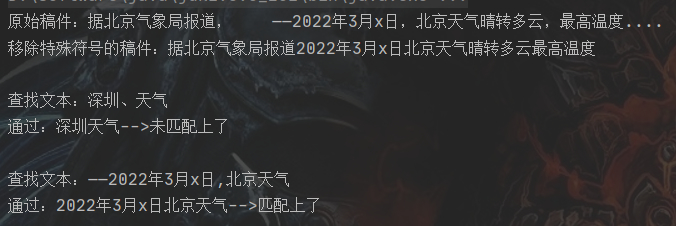
总结
正则表达式在实际开发中用的非常频繁的工具,所以我们在编写表达式的时候,务必要结合场景三思是否会跌入回溯陷阱;因为回溯问题的隐藏性比较高,如果仅仅是特殊的文本才出现,表现的问题也就只是CPU偶尔消耗比较大,代码执行效率偶尔不太高;导致问题排查起来非常的困难。