 IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
并发(八)之热数据:基于OpenResty(nginx+lua)+Kafka+Storm实现热数据感知及缓存预热

软件准备
OpenResty安装
如果对Nginx+Lua的使用不太了解,可以参考并发(五)之OpenResty:Nginx+lua实现一级缓存:https://blog.lupf.cn/articles/2020/04/17/1587095387737.html 其中对OpenResty的安装,部署以及基础的测试Lua编写都有说明;其中还讲解了,如何通过Nginx+Lua实现请求数据的 一级缓存,以 模版+数据的缓存来提高整个服务的QPS;
Kafka集群部署
并发(七)之分布式异步更新:Zookeeper+Kafka实现数据分布式异步更新:https://blog.lupf.cn/articles/2020/04/17/1587096190497.html 有对Zookeeper、Kafka的部署
Storm2.x集群部署
Storm2.x集群搭建及SpringBoot+Storm实现词频统计测试:https://blog.lupf.cn/articles/2020/04/17/1587126422655.html 包含了Storm的集群搭建以及如何使用Storm开发入门词频统计程序;
背景
为什么要做这个?答案:缓存预热!!!;预想一个场景,我们现在有很多用户,很不幸的时,服务一不小心down机了;在down机的期间,雪上加霜的是redis缓存的数据也全部都过期了,此时当你把服务一启动,大量的用户涌进来,结果缓存都没命中,直接全部打到了数据库;那一瞬间,DB撕掉虚伪的伪装光着腚在风中奔跑,DD随着风尽情的摇曳,一不小心步子迈大了就扯到了D,duang的一下就炸了,想想都疼。DB一挂,搞不好整个系统就雪崩了,本来只挂了一个模块,DB让其他关联的模块响应速度大大降低,造成请求拥堵,最后受不了虐待自刎了;为了防止DB裸奔,缓存预热就是其中的一个方案;当服务启动的时候,提前把热数据加载到Redis中,加载好了再对外提供服务,这样就不会造成所有的请求全部达到DB;既然要预热,那我们就必须知道那些是热数据;那如何知道那些是热数据呢?下面就是基于Lua+kafka+storm的实时热数据分析方案。感知及预热过程如下:
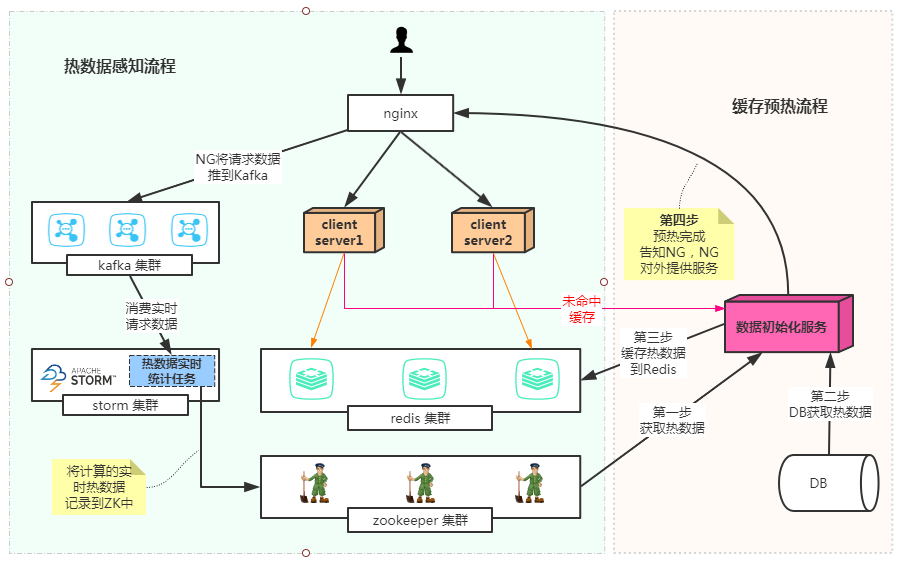
OpenResty
Lua相关代码开发
-
下载插件
// 进入工作目录 cd /usr/local/src/ // 下载最新的lua操作kafka的插件 wget https://github.com/doujiang24/lua-resty-kafka/archive/master.zip // 安装unzip yum install -y unzip // 解压 unzip master.zip // 将插件拷贝到OpenResty下的resty目录 cp -rf /usr/local/src/lua-resty-kafka-master/lib/resty/kafka /usr/local/openresty/lualib/resty/ // 如果其他机器也需要,可以使用scp访问 避免都需要安装unzip scp -r lua-resty-kafka-master/ root@cache1001:/usr/local/src/lua-resty-kafka-master/ -
开发Lua脚本
local cjson = require "cjson" local producer = require "resty.kafka.producer" -- 获取所有的请求参数 local uri_args = ngx.req.get_uri_args() -- 拿到商品ID的字段 local pId = uri_args["productId"] -- Kafka集群的列表 local broker_list = { { host = "192.168.1.160", port = 9092 }, { host = "192.168.1.161", port = 9092 }, { host = "192.168.1.162", port = 9092 } } local log_json = {} log_json["uri"]=ngx.var.uri log_json["remote_addr"] = ngx.var.remote_addr log_json["remote_user"] = ngx.var.remote_user log_json["time_local"] = ngx.localtime() log_json["status"] = ngx.var.status log_json["body_bytes_sent"] = ngx.var.body_bytes_sent log_json["http_referer"] = ngx.var.http_referer log_json["http_user_agent"] = ngx.var.http_user_agent log_json["http_x_forwarded_for"] = ngx.var.http_x_forwarded_for log_json["upstream_response_time"] = ngx.var.upstream_response_time log_json["request_time"] = ngx.var.request_time log_json["headers"] = ngx.req.get_headers() log_json["uri_args"] = ngx.req.get_uri_args() log_json["body"] = ngx.req.read_body() log_json["http_version"] = ngx.req.http_version() log_json["method"] =ngx.req.get_method() log_json["raw_reader"] = ngx.req.raw_header() log_json["body_data"] = ngx.req.get_body_data() -- 将对象转换为json文本 local message = cjson.encode(log_json); -- 创建一个Kafka的异步生产者 local async_producer = producer:new(broker_list, { producer_type = "async" }) -- 第一个参数: topic -- 第二个参数: 路由的字段,相同的数据会发送到同一个broker上,来保证数据的顺序性, -- 可以根据实际调整,这里使用一个商品id进行测试 local ok, err = async_producer:send("request_log", pId, message) if not ok then ngx.log(ngx.ERR, "kafka send err:", err) ngx.say("err".."-"..ngx.now()) -- 可以根据情况看是否需要return 这种业务场景一般都是为了健壮系统,必要的情况下,就算失败了,也可以继续走后续的流程 return end -- 拼接一个时间戳返回 方便查看效果 ngx.say("ok".."-"..ngx.now()) -
Kafka创建topic
// 由于上面lua生产的数据是发送到了request_log的topic;因此我们需要去创建一个request_log cd /usr/local/kafka/ bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --topic request_log --replication-factor 1 --partitions 1 --create
-
配置nginx
local cjson = require "cjson" local producer = require "resty.kafka.producer" -- 获取所有的请求参数 local uri_args = ngx.req.get_uri_args() -- 拿到商品ID的字段 local pId = uri_args["productId"] -- Kafka集群的列表 local broker_list = { { host = "192.168.1.160", port = 9092 }, { host = "192.168.1.161", port = 9092 }, { host = "192.168.1.162", port = 9092 } } local log_json = {} log_json["uri"]=ngx.var.uri log_json["remote_addr"] = ngx.var.remote_addr log_json["remote_user"] = ngx.var.remote_user log_json["time_local"] = ngx.localtime() log_json["status"] = ngx.var.status log_json["body_bytes_sent"] = ngx.var.body_bytes_sent log_json["http_referer"] = ngx.var.http_referer log_json["http_user_agent"] = ngx.var.http_user_agent log_json["http_x_forwarded_for"] = ngx.var.http_x_forwarded_for log_json["upstream_response_time"] = ngx.var.upstream_response_time log_json["request_time"] = ngx.var.request_time log_json["headers"] = ngx.req.get_headers() log_json["uri_args"] = ngx.req.get_uri_args() log_json["body"] = ngx.req.read_body() log_json["http_version"] = ngx.req.http_version() log_json["method"] =ngx.req.get_method() log_json["raw_reader"] = ngx.req.raw_header() log_json["body_data"] = ngx.req.get_body_data() -- 将对象转换为json文本 local message = cjson.encode(log_json); -- 创建一个Kafka的异步生产者 local async_producer = producer:new(broker_list, { producer_type = "async" }) -- 第一个参数: topic -- 第二个参数: 路由的字段,相同的数据会发送到同一个broker上,来保证数据的顺序性, -- 可以根据实际调整,这里使用一个商品id进行测试 local ok, err = async_producer:send("request_log", pId, message) if not ok then ngx.log(ngx.ERR, "kafka send err:", err) ngx.say("err".."-"..ngx.now()) -- 可以根据情况看是否需要return 这种业务场景一般都是为了健壮系统,必要的情况下,就算失败了,也可以继续走后续的流程 return end -- 拼接一个时间戳返回 方便查看效果 ngx.say("ok".."-"..ngx.now()) -
nginx配置
location /hello { default_type text/plain; # 指向上面创建的lua的脚本路径 content_by_lua_file /var/openresty/hello/lua/request_log.lua; } -
重启NG
/usr/local/openresty/nginx/sbin/nginx -t /usr/local/openresty/nginx/sbin/nginx -s reload -
问题一
// 如果出现了错误,直接在/usr/local/openresty/nginx/logs/error.log查看 module 'resty.kafka.producer' not found // 解决方式 // 确保上面的插件lua-resty-kafka-master/lib/resty/kafka下的所有文件是拷贝到了openresty/lualib/resty/kafka目录 ll /usr/local/openresty/lualib/resty/kafka/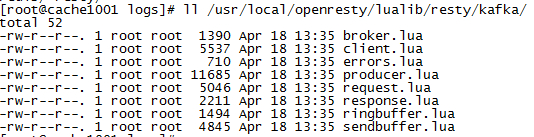
-
问题二
buffered messages send to kafka err: cache1000 could not be resolved (3: Host not found);意思是无法解析主机名 // 解决方式 // 在nginx.conf中添加DNS解析服务器 vim /usr/local/openresty/nginx/conf/nginx.conf // 在http的区域添加以下配置 resolver 223.5.5.5 223.6.6.6 1.2.4.8 114.114.114.114 valid=3600s; // 确认kafka的server.properties配置是否添加了advertised.host.name配置 // IP为主机的IP // 注意 这里不调整,亲测上面的resolver就算设置也还是会出现这个错误 advertised.host.name = 192.168.1.160 //保存并重启 /usr/local/openresty/nginx/sbin/nginx -t /usr/local/openresty/nginx/sbin/nginx -s reload
-
测试
// kafka创建一个request_log的消费者 cd /usr/local/kafka bin/kafka-console-consumer.sh --bootstrap-server cache1000:9092,cache1001:9092,cache1002:9092 --topic request_log // 浏览器请求nginx的地址,并传递productId参数 其他参数冗余测试 http://cache1002/hello?productId=1&a=2&b=234 // 如下效果,kafka已经可以接收到来自NG的请求数据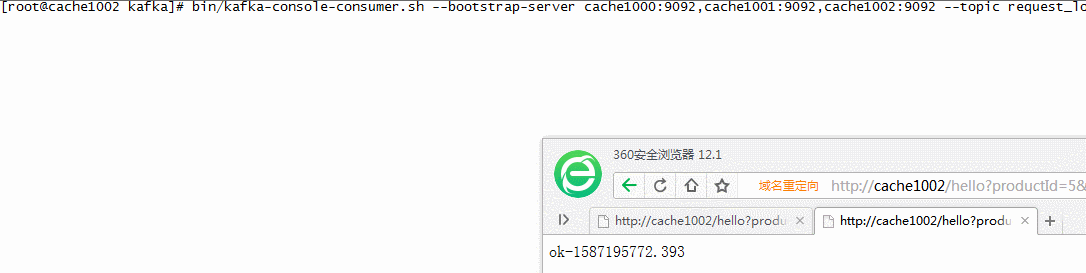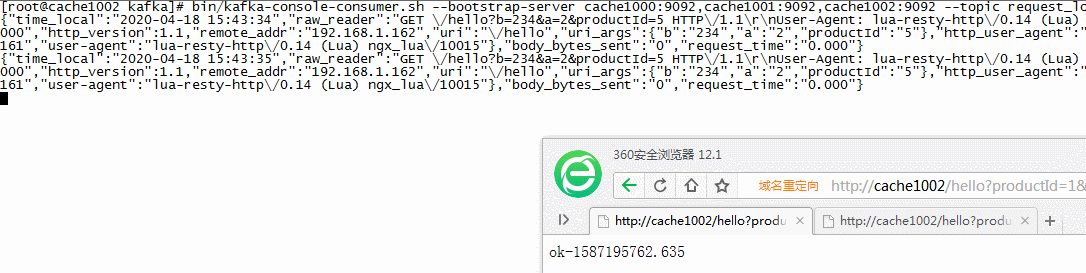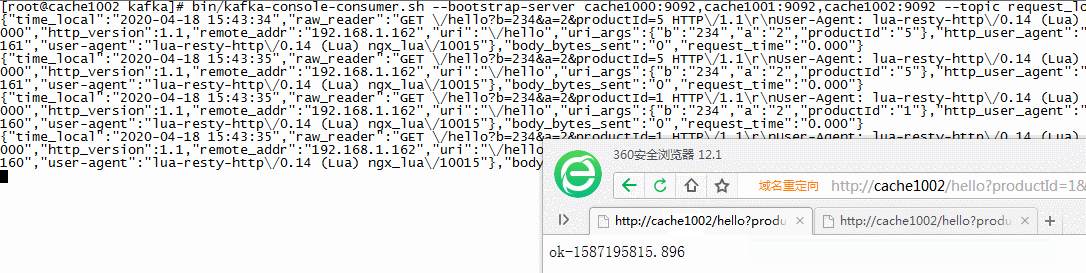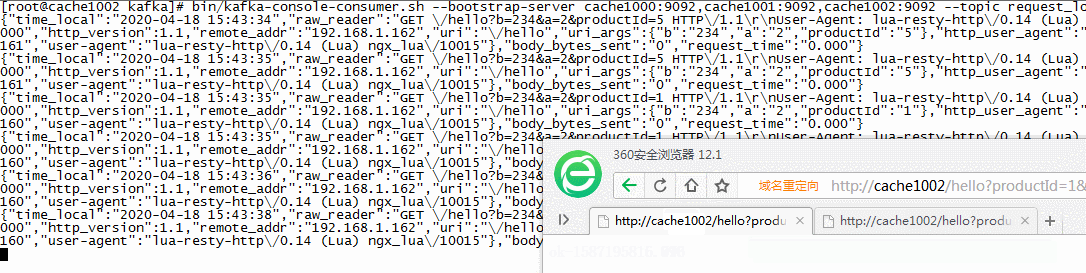
// 收到的数据 { "time_local": "2020-04-18 15:43:38", "raw_reader": "GET \/hello?b=234&a=2∏uctId=1 HTTP\/1.1\r\nUser-Agent: lua-resty-http\/0.14 (Lua) ngx_lua\/10015\r\nHost: 192.168.1.160\r\n\r\n", "method": "GET", "status": "000", "http_version": 1.1, "remote_addr": "192.168.1.162", "uri": "\/hello", "uri_args": { "b": "234", "a": "2", "productId": "1" }, "http_user_agent": "lua-resty-http\/0.14 (Lua) ngx_lua\/10015", "headers": { "host": "192.168.1.160", "user-agent": "lua-resty-http\/0.14 (Lua) ngx_lua\/10015" }, "body_bytes_sent": "0", "request_time": "0.000" }
Storm感知热数据
代码
-
创建maven项目,添加依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <exclusions> <!-- 因为日志包的冲突 这里把log4j-to-slf4j提出掉--> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.2.3</version> <!--在本地模式运行的时候需要把下面的给注释掉--> <!--打包的时候需要将注释打开,否则会报错--> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.9.2</artifactId> <version>0.8.1</version> </dependency> <dependency> <groupId>com.codahale.metrics</groupId> <artifactId>metrics-core</artifactId> <version>3.0.2</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> -
插件
<build> <sourceDirectory>src/main/java</sourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <configuration> <createDependencyReducedPom>true</createDependencyReducedPom> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.sf</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.dsa</exclude> <exclude>META-INF/*.RSA</exclude> <exclude>META-INF/*.rsa</exclude> <exclude>META-INF/*.EC</exclude> <exclude>META-INF/*.ec</exclude> <exclude>META-INF/MSFTSIG.SF</exclude> <exclude>META-INF/MSFTSIG.RSA</exclude> </excludes> </filter> </filters> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <!-- <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>org.durcframework.core.MainCore</mainClass> </transformer>--> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <goals> <goal>exec</goal> </goals> </execution> </executions> <configuration> <executable>java</executable> <includeProjectDependencies>true</includeProjectDependencies> <includePluginDependencies>false</includePluginDependencies> <classpathScope>compile</classpathScope> <mainClass></mainClass> </configuration> </plugin> </plugins> </build> -
常量
public class KafkaConstant { // 商品修改监听的topic public static final String TOPIC_PRODUCT_INFO_UPDATE = "product_info_update"; public static final String TOPIC_PRODUCT_INFO_ADD = "product_info_add"; // 商品数据初始化的group id public static final String GROUP_ID_SHOP_DATA_INIT = "shop_data_init"; // storm监听请求日志的group id public static final String GROUP_ID_STORM_REQUESP_LOG = "request-log-group"; // storm监听请求日志的topic public static final String TOPIC_STORM_REQUESP_LOG = "request_log"; } public class ZkConstant { // zk集群的地址 public static final String ZK_CONNECT_STRING = "cache1000:2181,cache1000:2181,cache1000:2181"; // 热门商品的task列表 public static final String PRODUCT_HOT_DATA_TASK_LIST_PATH = "/product_hot_data_task_list"; public static final String PRODUCT_HOT_DATA_TASK_LIST_LOCK = "/product_hot_data_task_list_lock"; // 缓存task热门数据的path public static final String PRODUCT_HOT_DATA_LIST_BY_TASKID = "/product_hot_data_taskid_"; } -
zookeeper分布式锁工具类
import com.lupf.server.common.utils.constant.zk.ZkConstant; import com.lupf.server.common.utils.thread.ServerThreadPool; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.StringUtils; import org.apache.zookeeper.*; import org.apache.zookeeper.data.Stat; import java.util.concurrent.CountDownLatch; @Slf4j public class ZKUtils { // 单例对象 private static ZKUtils zkUtils; // zk的连接对象 private ZooKeeper zooKeeper; // 用于等待连接成功的countDownLatch private static CountDownLatch countDownLatch; // 默认的连接地址,可以在init()方法中指定 private static String connectString = ZkConstant.ZK_CONNECT_STRING; // 调用init方法是异步连接zk还是同步 // 默认是异步 private static boolean asynConnect = true; private ZKUtils(String connectString) { try { // 如果是同步连接zk if (!asynConnect) { // 初始化CountDownLatch countDownLatch = new CountDownLatch(1); } String cs = this.connectString; if (StringUtils.isNotBlank(connectString)) { cs = connectString; } // 创建线程连接zk DataInitThreadPool为线程池 ServerThreadPool.getInstance().submit(new Thread(new ConnectThread(cs))); // 如果是同步连接 if (!asynConnect && null != countDownLatch) { log.info("zk sync connecting"); // 等待zk的连接成功 countDownLatch.await(); log.info("zk sync connected"); } else { log.info("zk asyn connecting"); } } catch (InterruptedException e) { e.printStackTrace(); } } /** * 连接zk的线程 */ private class ConnectThread implements Runnable { // 连接地址 private String connectString; public ConnectThread(String connectString) { this.connectString = connectString; } @Override public void run() { connect(); } private void connect() { // 设置个死循环 如果连接不成功 就一直狂连 while (true) { try { // 创建连接对象 zooKeeper = new ZooKeeper(connectString // 地址 , 30000 // 超时时间 , new ZookeeperWatcher()); //监听器 break; } catch (Exception e) { e.printStackTrace(); } try { // 如果连接失败了 等半秒钟再次尝试 Thread.sleep(500); } catch (InterruptedException e) { } } } } private class ZookeeperWatcher implements Watcher { @Override public void process(WatchedEvent watchedEvent) { Event.KeeperState state = watchedEvent.getState(); if (Event.KeeperState.SyncConnected == state) { // zk连接成功 if (!asynConnect && null != countDownLatch) { // 计数减一 countDownLatch.countDown(); } log.info("zk连接成功!!!!"); } else if (Event.KeeperState.Disconnected == state) { log.info("zk连接断开!!!!"); zooKeeper = null; } } } public static ZKUtils getInstance() { if (null == zkUtils) { synchronized (ZKUtils.class) { if (null == zkUtils) { zkUtils = new ZKUtils(connectString); } } } return zkUtils; } /** * 项目启动时 初始化 * * @param cs 连接的地址 * @param asyn_connect 是否异步连接 true:异步,false:同步(只有连接成功了方法才会执行完) */ public static void init(String cs, boolean asyn_connect) { if (StringUtils.isNotBlank(cs)) { connectString = cs; } // 移除创建连接,初始化的时候不等待 asynConnect = asyn_connect; getInstance(); } //------------------------------------------------------------------------------ /** * 获取锁 * * @param path 创建的临时节点的路径 * @param waitTime 超时时间 如果超过这个时间还没有获取到锁,就直接返回 -1表示不超时 * @return true 获取锁成功 false失败 */ public boolean acquireDistributedLock(String path, long waitTime) { long time = System.currentTimeMillis(); int count = 0; while (true) { count++; if (null != zooKeeper) { try { // log.info("线程ID:{}第{}次尝试获取:{}的锁!", Thread.currentThread().getId(), count, path); // 创建一个临时的节点 zooKeeper.create(path, "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); // 创建成功说明获取锁成功 log.info("线程ID:{}第{}次尝试成功获取:{}的锁!", Thread.currentThread().getId(), count, path); return true; } catch (Exception e) { //e.printStackTrace(); // log.error("线程ID:{}第{}次尝试获取:{}的锁失败!", Thread.currentThread().getId(), count, path); } } else { // zk尚未初始化成功!等待初始化.... } if (waitTime > 0) { long now = System.currentTimeMillis(); if (now - time > waitTime) { log.info("尝试获取了{}次锁失败,超时....", count); break; } } // 到这里说明创建节点失败,需要重试 try { // 等20毫秒再去那锁 Thread.sleep(20); } catch (InterruptedException e) { } } return false; } /** * 释放锁 * * @param path 释放的路径 */ public void releaseDistributedLock(String path) { try { // 直接删掉临时节点 deleteNode(path); } catch (Exception e) { e.printStackTrace(); } } /** * 创建节点 * * @param path 节点路径 */ public void createNode(String path) { try { zooKeeper.create(path, "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } catch (Exception e) { } } /** * 设置节点的值 * * @param path 路径 * @param data 值 */ public void setNode(String path, String data) { try { zooKeeper.setData(path, data.getBytes(), -1); } catch (Exception e) { e.printStackTrace(); } } /** * 获取节点的数据 * * @param path 节点路径 * @return 保存的值 */ public String getNode(String path) { try { return new String(zooKeeper.getData(path, false, new Stat())); } catch (Exception e) { e.printStackTrace(); } return ""; } /** * 删除节点 * * @param path */ public void deleteNode(String path) { try { zooKeeper.delete(path, -1); } catch (Exception e) { e.printStackTrace(); } } } -
ConsumerRequestLogSpout;用于消费kafka的数据并发射出去import com.lupf.server.common.utils.constant.kafka.KafkaConstant; import com.lupf.server.common.utils.constant.zk.ZkConstant; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import lombok.extern.slf4j.Slf4j; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import org.apache.storm.utils.Utils; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import java.util.concurrent.ArrayBlockingQueue; @Slf4j public class ConsumerRequestLogSpout extends BaseRichSpout { private static final long serialVersionUID = 4857468944043071315L; private SpoutOutputCollector collector; // 用于保存消息的队列 private ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<>(1000); @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this.collector = spoutOutputCollector; getKafkaConsumer(); } @Override public void nextTuple() { try { if (queue.size() > 0) { // 读取一条数据 String take = queue.take(); log.info("storm开始处理消息{}", take); // 发射出去 collector.emit(new Values(take)); } else { Utils.sleep(100); } } catch (Exception e) { } } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 指定发射出去的数据file的name outputFieldsDeclarer.declare(new Fields("message")); } /** * 创建kafka的消费者 */ private void getKafkaConsumer() { // 设置kafka相关的参数 Properties properties = new Properties(); properties.put("zookeeper.connect", ZkConstant.ZK_CONNECT_STRING); //设置zk的地址 properties.put("group.id", KafkaConstant.GROUP_ID_STORM_REQUESP_LOG); // 设置消费组 properties.put("zookeeper.session.timeout.ms", "40000"); // 设置连接 properties.put("zookeeper.sync.time.ms", "200"); properties.put("auto.commit.interval.ms", "1000"); // 创建一个消费者的配置对象 ConsumerConfig consumerConfig = new ConsumerConfig(properties); // 获取一个消费者的连接对象 ConsumerConnector consumerConnector = Consumer.createJavaConsumerConnector(consumerConfig); Map<String, Integer> topicCountMap = new HashMap<>(); topicCountMap.put(KafkaConstant.TOPIC_STORM_REQUESP_LOG, 1); Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumerConnector.createMessageStreams(topicCountMap); List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(KafkaConstant.TOPIC_STORM_REQUESP_LOG); for (KafkaStream stream : streams) { log.info("开始创建数据读取线程!"); new Thread(new KafkaMessageProcessor(stream)).start(); } } /** * 接受kafka的消息 */ private class KafkaMessageProcessor implements Runnable { @SuppressWarnings("rawtypes") private KafkaStream kafkaStream; @SuppressWarnings("rawtypes") public KafkaMessageProcessor(KafkaStream kafkaStream) { this.kafkaStream = kafkaStream; } @SuppressWarnings("unchecked") public void run() { ConsumerIterator<byte[], byte[]> it = kafkaStream.iterator(); while (it.hasNext()) { String message = new String(it.next().message()); try { log.info("接收到数据:{}", message); queue.put(message); } catch (InterruptedException e) { e.printStackTrace(); } } } } } -
GetProductIdBolt;获取一条日志数据对应的商品ID并发射出去import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.apache.commons.lang3.StringUtils; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.util.Map; public class GetProductIdBolt extends BaseRichBolt { private static final long serialVersionUID = 2977267422773768968L; OutputCollector collector; @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { this.collector = outputCollector; } @Override public void execute(Tuple tuple) { try { //{ // .... // "remote_addr": "192.168.1.162", // "uri": "\/hello", // "uri_args": { // "b": "234", // "a": "2", // "productId": "1" // } // .... //} // 以上是消息的一个缩减的格式 我们需要uri_args中把productId取出来 // 获取spout发射出来的一条message消息 String message = tuple.getStringByField("message"); if (StringUtils.isNotBlank(message)) { // 解析为json JSONObject messageJson = JSON.parseObject(message, JSONObject.class); // 拿到uri_args if (null != messageJson && messageJson.containsKey("uri_args")) { JSONObject uriArgsJson = messageJson.getJSONObject("uri_args"); if (null != uriArgsJson && uriArgsJson.containsKey("productId")) { // 获取到商品ID String productId = uriArgsJson.getString("productId"); if (StringUtils.isNotBlank(productId)) { // 将获取到的商品id发射出去 collector.emit(new Values(Integer.parseInt(productId))); } } } } } catch (Exception e) { e.printStackTrace(); } } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 设置发射出去的商品id的filed对应的name outputFieldsDeclarer.declare(new Fields("productId")); } } -
ProductCountBolt;基于LRUMap统计商品的热数据,并以30s的周期将其保存到zk中;这里用的比较简单的LRU算法统计的热数据,可以根据业务,调整自己的算法策略;import com.alibaba.fastjson.JSON; import com.lupf.server.common.utils.constant.zk.ZkConstant; import com.lupf.server.common.utils.zk.ZKUtils; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.StringUtils; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.trident.util.LRUMap; import org.apache.storm.tuple.Tuple; import org.apache.storm.utils.Utils; import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.concurrent.atomic.AtomicLong; @Slf4j public class ProductCountBolt extends BaseRichBolt { private static final long serialVersionUID = 3854692305371122153L; OutputCollector collector; ZKUtils zkUtils; // 缓存计数的Map 最多保存3条;会基于LRU算法将就数据给删掉 // 这里可以根据自己的需要设置,由于测试数据比较少;所以,就只保存3条热数据,方便测试 private LRUMap<Integer, AtomicLong> productCountMap = new LRUMap<>(3); // 数据更新的周期,30s更新一次zk 保存最新的30产生的热数据 private final Integer UPDATE_CYCLE = 30 * 1000; @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { this.collector = outputCollector; zkUtils = ZKUtils.getInstance(); // 当前task的id int thisTaskId = topologyContext.getThisTaskId(); new Thread(new ProductCountRunable(thisTaskId)).start(); initTaskList(thisTaskId); } /** * 初始化task list 列表 * 目的是方便加载数据的时候,知道有那些task 好方便取数据 * 需要分布式线程安全更新 */ public void initTaskList(int taskId) { // 加锁 zkUtils.acquireDistributedLock(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_LOCK, -1); zkUtils.createNode(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_PATH); // 将任务id以 id,id,id,...这样的形式存储起来 String data = zkUtils.getNode(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_PATH); if (StringUtils.isNotBlank(data)) { data = data + "," + taskId; } else { data = String.valueOf(taskId); } zkUtils.setNode(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_PATH, data); // 释放锁 zkUtils.releaseDistributedLock(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_LOCK); } @Override public void execute(Tuple tuple) { Integer productId = tuple.getIntegerByField("productId"); AtomicLong count = productCountMap.get(productId); if (null == count) { synchronized (ProductCountBolt.class) { if (null == count) { count = new AtomicLong(0); } } } long l = count.incrementAndGet(); log.info("商品ID:{}请求了{}次", productId, l); productCountMap.put(productId, count); } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } /** * 统计热数据 保存zk的线程 */ public class ProductCountRunable implements Runnable { // task id int taskId; ProductCountRunable(int taskId) { this.taskId = taskId; } @Override public void run() { while (true) { // 如果没有任何人访问 if (productCountMap.size() <= 0) { // 等一会儿 Utils.sleep(100); continue; } // 通过排序找出最热门的商品 List<Map.Entry<Integer, AtomicLong>> list = new ArrayList<>(productCountMap.entrySet()); // 降序 list.sort((o1, o2) -> { if (o1.getValue().get() > o2.getValue().get()) { return -1; } else if (o1.getValue().get() < o2.getValue().get()) { return 1; } return 0; }); String s = JSON.toJSONString(list); // 当前task统计的热数据的path String path = ZkConstant.PRODUCT_HOT_DATA_LIST_BY_TASKID + taskId; // 创建node 如果不创建 下面的set将无法设置成功 zkUtils.createNode(path); // 保存数据 zkUtils.setNode(path, s); // 休眠一点时间 再进行汇总 Utils.sleep(UPDATE_CYCLE); } } } } -
ProductCountTopology
import com.lupf.server.common.utils.constant.zk.ZkConstant; import com.lupf.server.common.utils.zk.ZKUtils; import com.lupf.shopstorm.hotdata.bolt.GetProductIdBolt; import com.lupf.shopstorm.hotdata.bolt.ProductCountBolt; import com.lupf.shopstorm.hotdata.spout.ConsumerRequestLogSpout; import org.apache.commons.lang3.StringUtils; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; import org.apache.storm.utils.Utils; public class ProductCountTopology { public static void main(String[] args) { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("ConsumerRequestLogSpout", new ConsumerRequestLogSpout(), 1); builder.setBolt("GetProductIdBolt", new GetProductIdBolt(), 1) .setNumTasks(2) .shuffleGrouping("ConsumerRequestLogSpout"); // fieldsGrouping指明通过getProductIdBolt的productId进行分组,保证同一个productId由同一个task处理 builder.setBolt("", new ProductCountBolt(), 1) .setNumTasks(2) .fieldsGrouping("GetProductIdBolt", new Fields("productId")); ZKUtils.init(null, false); ZKUtils zkUtils = ZKUtils.getInstance(); // 重启之前清除掉前一次产生的数据 cleanUpHistoricalData(zkUtils); // topology的配置文件 Config config = new Config(); try { if (args != null && args.length > 0) { // 说明是命令行执行 config.setNumWorkers(3); // args[0]传递的topology的名称 StormSubmitter.submitTopology(args[0], config, builder.createTopology()); } else { // 最大的任务并行度 config.setMaxTaskParallelism(20); LocalCluster localCluster = new LocalCluster(); // 提交一个topology localCluster.submitTopology("ProductCountTopology", config, builder.createTopology()); // 测试环境运行1分钟 Utils.sleep(1 * 60 * 1000); // 然后关掉本地的测试 localCluster.shutdown(); } } catch (Exception e) { } } /** * 用于清除历史产生的热点数据 */ public static void cleanUpHistoricalData(ZKUtils zkUtils) { // 加锁 zkUtils.acquireDistributedLock(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_LOCK, -1); // 获取task的列表 String taskList = zkUtils.getNode(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_PATH); if (StringUtils.isNotBlank(taskList)) { // 得到所有的task id String[] taskIds = taskList.split(","); // 清除历史的taskid统计的数据 for (String taskId : taskIds) { // 删除掉id对应的记录 String taskPath = ZkConstant.PRODUCT_HOT_DATA_LIST_BY_TASKID + taskId; zkUtils.deleteNode(taskPath); } // 清空掉task 列表 zkUtils.setNode(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_PATH, ""); } // 释放锁 zkUtils.releaseDistributedLock(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_LOCK); } }
本地idea测试
-
检查pom.xml
// <!--<scope>provided</scope>--> 这一样配置是否注释掉了,不注释会报下图的错误 <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.2.3</version> <!--在本地模式运行的时候需要把下面的给注释掉--> <!--打包的时候需要将注释打开,否则会报错--> <!--<scope>provided</scope>--> </dependency>
-
本地启动
// 直接右键运行ProductCountTopology // 记得关掉上面我们为了测试开启的控制台的kafka消费者 -
请求产生数据
// 修改不同的productId 产生不同的记录,记住各个商品的次数; // 大约过30s之后查看zk中的数据 http://cache1002/hello?productId=1&a=2&b=234 -
ZK核对数据
// 找zookeeper集群的任意一台机器 cd /usr/local/zookeeper/bin ./zkCli.sh // 查看根节点的路径 ls / // 查看task id列表 get /product_hot_data_task_list // 查看各个task id统计的数据 get /product_hot_data_taskid_1
srorm集群测试
-
确认pom.xml
// 确认这个注释已经打开了,否则打包之后运行会报下图的错误 <scope>provided</scope>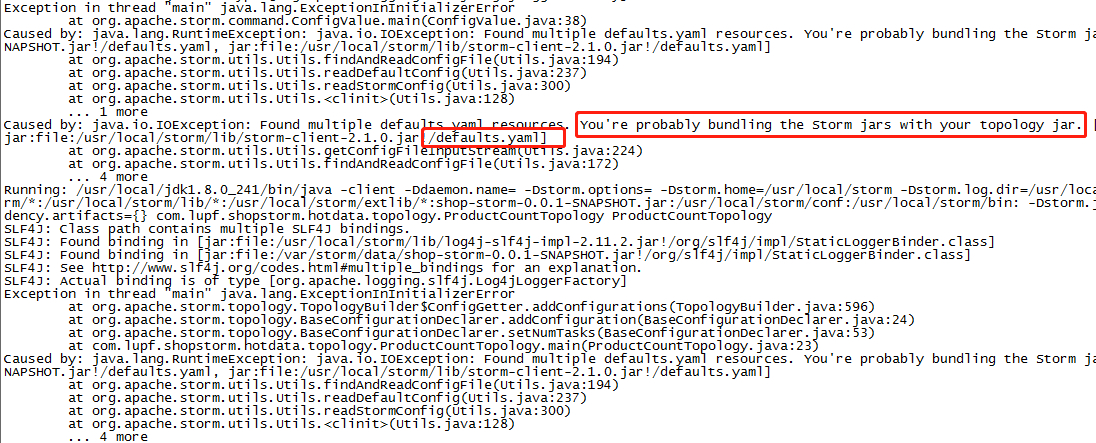
-
打包并上传到storm主节点主机
// 将maven项目打包成jar mvn clean package -Dmaven.test.skip=true -
运行任务
// storm-0.0.1-SNAPSHOT.jar 为jar的名称 可以是相对路径,也可以是绝对路径 // com.lupf.shopstorm.hotdata.topology.ProductCountTopology 为ProductCountTopology的路径 // ProductCountTopology 任务的名称 storm jar storm-0.0.1-SNAPSHOT.jar com.lupf.shopstorm.hotdata.topology.ProductCountTopology ProductCountTopology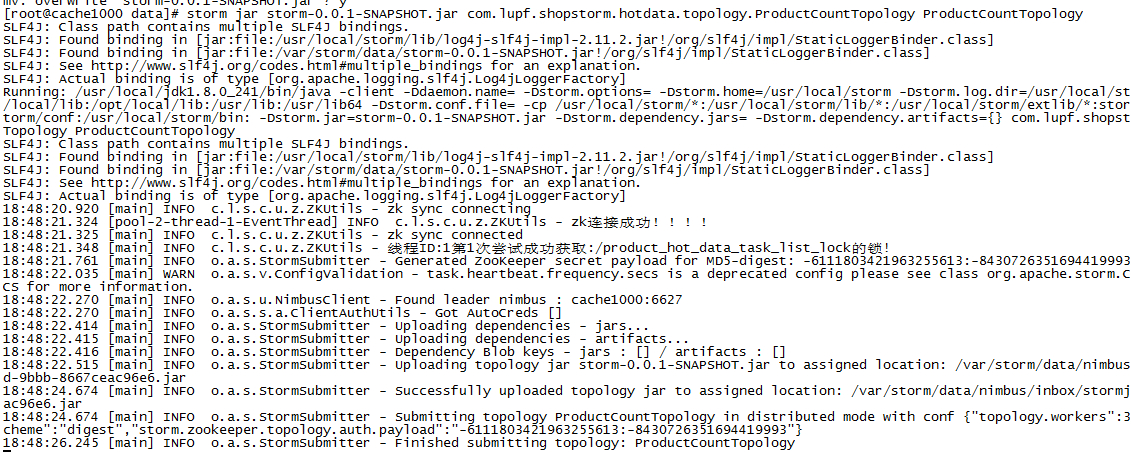
-
杀掉任务
// ProductCountTopology为上面创建时的名称 storm kill ProductCountTopology -
管理平台查看
// 访问storm ui对应的服务器 http://cache1000:8082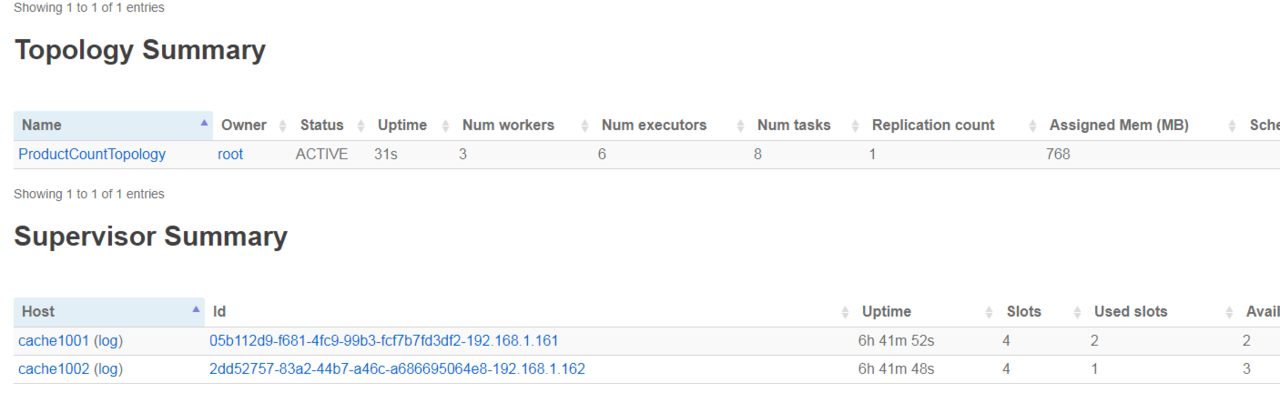
-
zk的确认方式同上
缓存预热
-
预热说明;
上面我们已经将热数据统计好并保存到了zookeeper中,我们需要做的是,当项目启动并对外提供服务之前,我们预先将zookeeper汇总的热数据加载到Redis中之后,加载完再对外提供服务;这样对外服务对外之后,热数据的请求就直接会命中Redis缓存,只有非热数据才会走到DB,从而大大降低DB的压力 -
数据加载帮助类InitHotData2RedisUtil;
import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.TypeReference; import com.lupf.server.common.utils.constant.zk.ZkConstant; import com.lupf.server.common.utils.zk.ZKUtils; import com.lupf.shopdatainit.service.ProductInfoCacheService; import com.lupf.shopdatainit.service.ProductInfoService; import com.lupf.spia.model.ProductInfoModel; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.StringUtils; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import java.util.*; /** * 第一步:在zookeeper中拿到task id的列表 * 第二步:遍历列表,拿到每个task id中的热数据id * 第三步:拿到ID,到数据库查询数据 * 第四步:将查询出来的数据缓存到Redis中 */ @Component @Slf4j public class InitHotData2RedisUtil { @Autowired ProductInfoService productInfoService; @Autowired ProductInfoCacheService productInfoCacheService; public void initData2Redis() { ZKUtils zkUtils = ZKUtils.getInstance(); String taskIdList = zkUtils.getNode(ZkConstant.PRODUCT_HOT_DATA_TASK_LIST_PATH); if (StringUtils.isNotBlank(taskIdList)) { log.info("感知到热点数据task id列表{}", taskIdList); // 通过,分割得到task id的列表 String[] taskIds = taskIdList.split(","); List<Map.Entry<Integer, Integer>> allHotData = new ArrayList<>(); // 遍历所有的task id for (String taskId : taskIds) { // 组装task id获取热点商品列表的key String taskPath = ZkConstant.PRODUCT_HOT_DATA_LIST_BY_TASKID + taskId; // 获取对应task id中的热点数据列表,如:[{1000:13456},{10098:5678},....] String hotDataStr = zkUtils.getNode(taskPath); // 判断数据是够为null if (StringUtils.isNotBlank(hotDataStr)) { log.info("获取到task id:{}中的热数据列表为{}", taskId, hotDataStr); // 将文本转化为对象 List<Map.Entry<Integer, Integer>> hotDataList = JSON.parseObject(hotDataStr, new TypeReference<List<Map.Entry<Integer, Integer>>>() { }); // 将每个task id中的热点商品数据汇总到一个地方 allHotData.addAll(hotDataList); } } // 目前allHotData得到的是各个task中前N的热数据 // 如: // task id:1 [{1:100},{2:50},{9:20}] // task id:2 [{4:500},{8:80},{7:75}] // 那么得到的allHotData如下 // allHotData: [{1:100},{2:50},{9:20},{4:500},{8:80},{7:75}] // 这里就需要根据实际业务场景来决定时候对汇总的数据进行处理了 // 1、就直接基于每个task id中的热数据都进行加载 // 2、将汇总的数据取top n;如排序取前三:[{4:500},{1:100},{8:80}] 进行加载 // 排序 //allHotData.sort(new Comparator<Map.Entry<Integer, Long>>() //{ // @Override // public int compare(Map.Entry<Integer, Long> o1, Map.Entry<Integer, Long> o2) // { // return 0; // } //}); if (null != allHotData) { // 得到迭代器 Iterator<Map.Entry<Integer, Integer>> iterator = allHotData.iterator(); while (iterator.hasNext()) { // 迭代数据 Map.Entry<Integer, Integer> next = iterator.next(); // key为商品id Integer key = next.getKey(); // value为访问的次数 Integer value = next.getValue(); log.info("获取到热商品ID:{}被访问了{}次", key, value); // 根据商品id获取商品信息 ProductInfoModel productInfoModel = productInfoService.findById(key); // 判断商品是否还存在 if (null != productInfoModel) { // 将商品信息缓存到redis中去 productInfoCacheService.productInfoCache2Redis(productInfoModel); } else { log.warn("未获取到商品ID:{}对应的数据!", key); } } } } } } -
项目启动触发工具类加载
import com.lupf.server.common.utils.thread.ServerThreadPool; import com.lupf.server.common.utils.zk.ZKUtils; import com.lupf.shopdatainit.hotdata.InitHotData2RedisUtil; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.context.event.ApplicationPreparedEvent; import org.springframework.context.ApplicationListener; import org.springframework.stereotype.Component; /** * 监听ApplicationPreparedEvent事件 * 项目初始化对外提供服务之前,触发该事件 */ @Component @Slf4j public class InitServiceDataImpl implements ApplicationListener<ApplicationPreparedEvent> { @Value("${spring.cloud.zookeeper.connect-string}") private String zkConnectString; @Autowired InitHotData2RedisUtil initHotData2Redis; @Override public void onApplicationEvent(ApplicationPreparedEvent event) { log.info("开始初始化线程池...."); ServerThreadPool.init(); log.info("初始化线程池完成...."); log.info("开始初始化zk {}", zkConnectString); ZKUtils.init(zkConnectString, false); log.info("初始化zk完成...."); // 初始化热数据 initHotData2Redis.initData2Redis(); log.info("初始化zk完成...."); } } -
启动项目测试
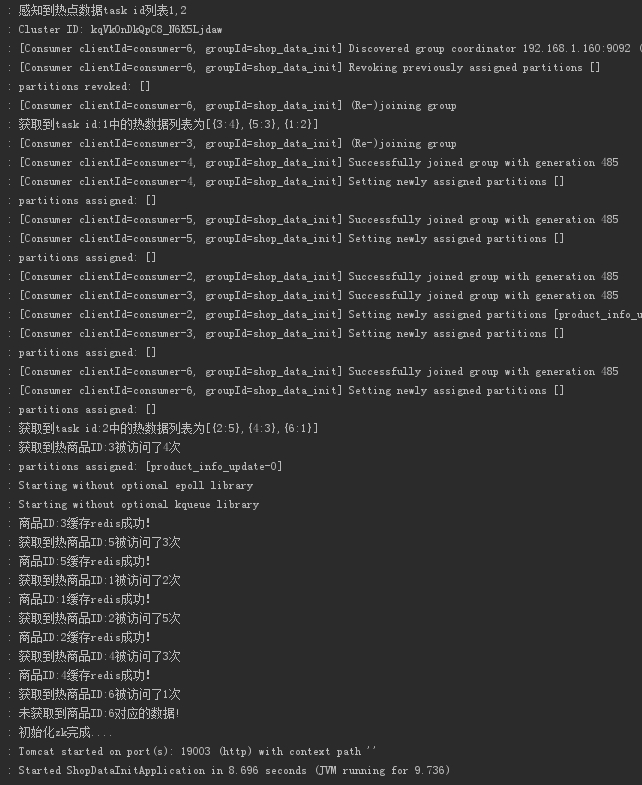
至此,热数据感知及预热加载成功!!!
标题:并发(八)之热数据:基于OpenResty(nginx+lua)+Kafka+Storm实现热数据感知及缓存预热
作者:码霸霸
地址:https://blog.lupf.cn/articles/2020/04/20/1587365586662.html